
The first part of this post was about the basic setup and running Zookeeper, Drill and Hadoop HDFS. In this second part we will add a CSV file to HDFS and query it from Drill.
Before we can query HDFS, we have to define a storage plugin for HDFS. Go to the local Drill web site at http://localhost:8047. Once there click on "Storage" at the top. You will see the page below.
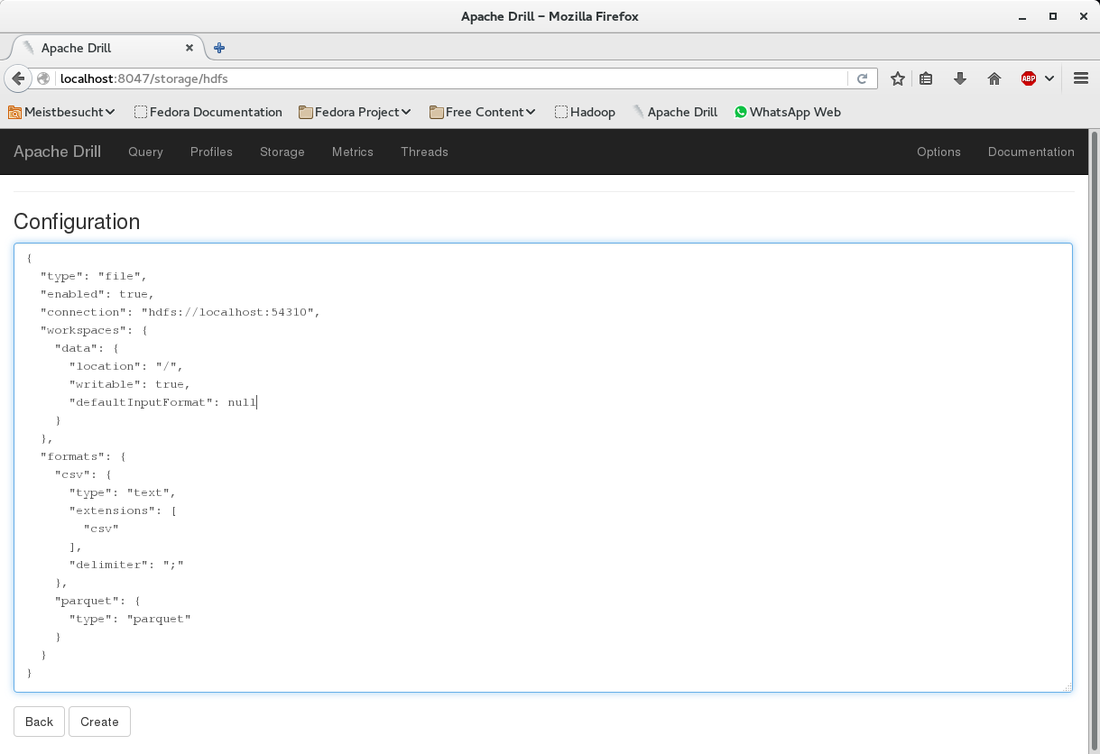
At the bottom under "New Storage Plugin" enter hdfs in the textbox and click on "create". You will see a page titeled "Configuration". I filled in the information as shown below. What you can also do is to copy the configuration of an existing storage plugin (e.g. "dfs") and modify it for the HDFS configuration. Basically you only need to change the values for "connection" and (workspace) "location".
Look at the value for "connection" below. That is the hostname and port as defined in the hadoop hdfs-site.xml file for the property "fs.default.name". Please also note that my workspace below is called "data" and as "location" I have set the root folder of hdfs.
When you'r done click on "Create" and make sure you get a message saying "success" at the bottom of the page. Next click on "Back" to return to the "Storage" page.
We are now ready to query the Hadoop filesystem - everything is configured. But we have no files in HDFS yet. So lets copy a CSV file into hdfs. We will use the hdfs command -a script in /opt/hadoop/bin - to do this.
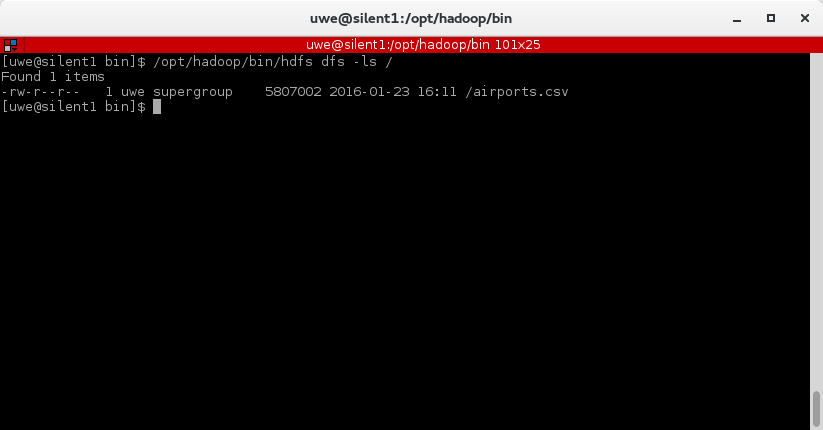
My CSV file - a file containing information about airports - is named "airports.csv" and is located in /tmp. Copy it into the hdfs root folder using the following command:
/opt/hadoop/bin/hdfs dfs -copyFromLocal /tmp/airports.csv /
To see if the file was really copied, use this command:
/opt/hadoop/bin/hdfs dfs -ls /
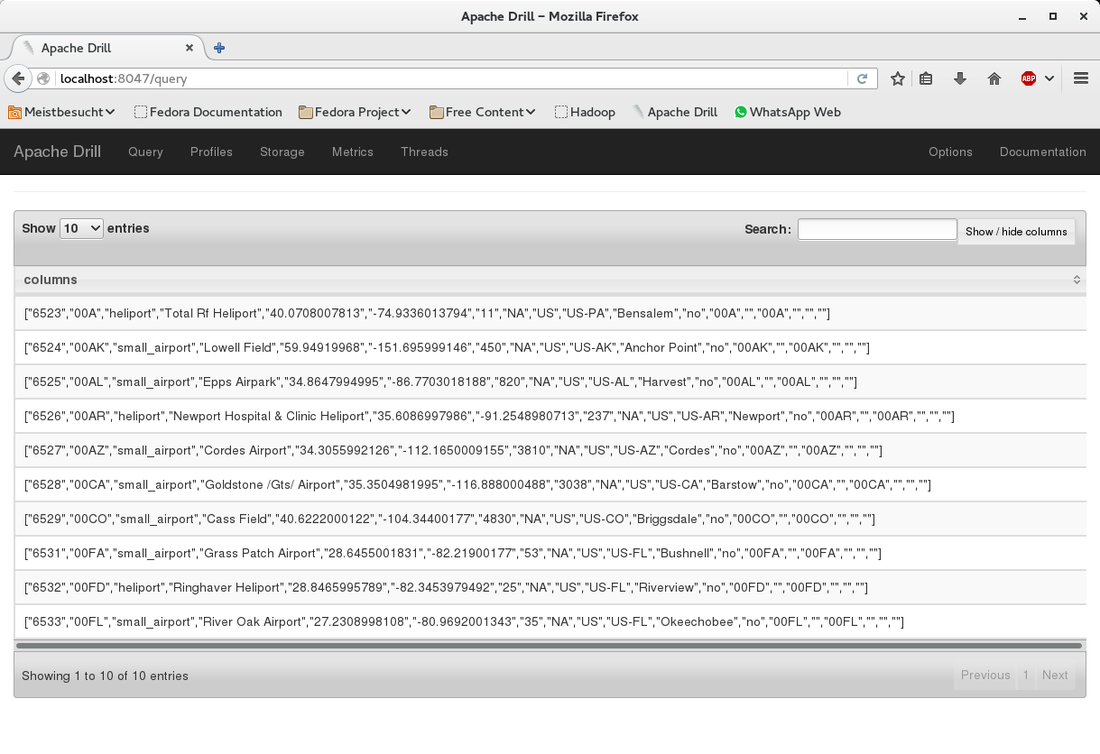
Go back to the drill web ui and click at the top on "Query". Enter the following query (note the backticks at the beginning and end of the filename) and submit it.
select * from hdfs.data.`airports.csv` limit 10
In this query "hdfs" is the name of the storage plugin and "data" is the name of the workspace both from the hdfs configuration of the storage plugin we did before.
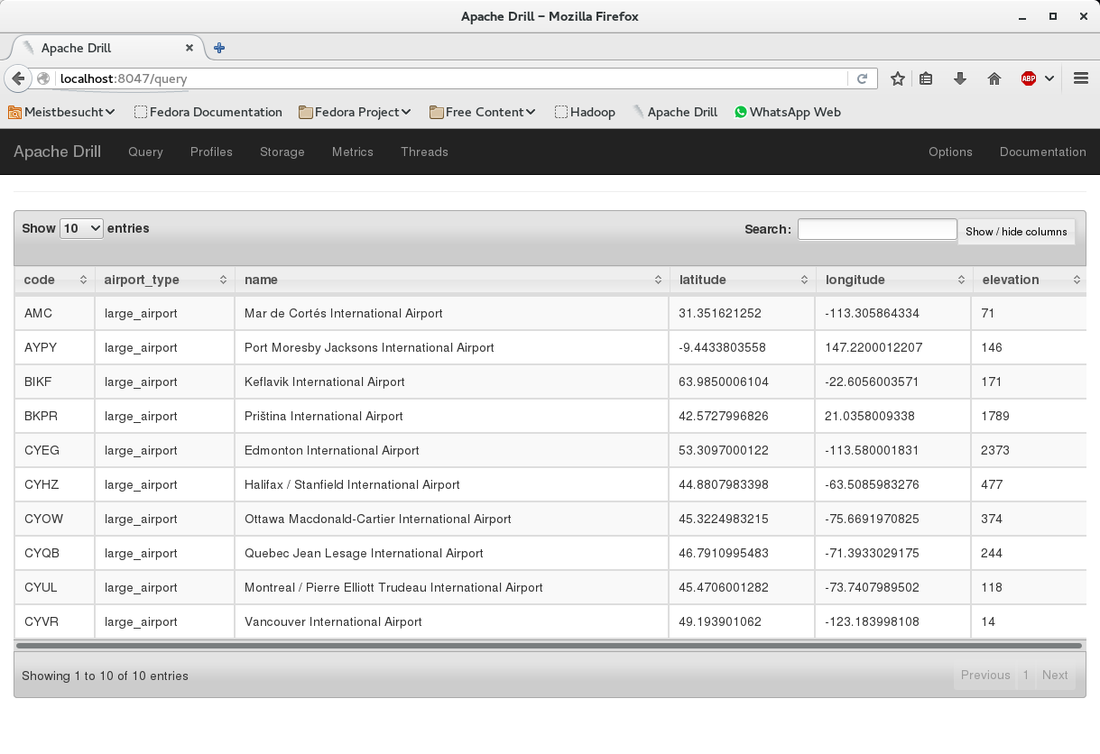
Have a look at the result:
Because we have used "select * ..." Drill returns the rows as an array of fields. Let's do a slightly different query which displays nicer and only some of the fields:
select columns[1] as code,columns[2] as airport_type,columns[3] as name, columns[4] as latitude, columns[5] as longitude,columns[6] as elevation from hdfs.data.`/airports.csv` where columns[2]='large_airport' limit 10
 RSS Feed
RSS Feed
