
One important point in the design of a graph - the nodes and relationships - is the idea of sharing or not sharing nodes. It may be obvious, but I wanted to collect my thoughts here anyway. Either, so that others can benefit and on the other side to stimulate discussions about graph design.
It comes down to the question of uniqueness of objects. E.g. you might have two objects that have the same name. So one might be tempted to create one node and then subsequently multiple relations will point to it. But the question is: are they the same object or are they independent objects on their own - which just happen to have the same name?
For example: A company "Xtec" has an office in Australia and one in Germany. Both have a department that is named "Sales". And then the "Sales" department is connected to multiple customers. The main objects here are marked in bold.
So here are my objects/nodes in Neo4j: In red the company, blue for customers and green for the offices and yellow for departments. I created three dummy customers here.
Please bare with me - I oversimplify the case here a little bit for the sake of the length and complexity of the post.
It comes down to the question of uniqueness of objects. E.g. you might have two objects that have the same name. So one might be tempted to create one node and then subsequently multiple relations will point to it. But the question is: are they the same object or are they independent objects on their own - which just happen to have the same name?
For example: A company "Xtec" has an office in Australia and one in Germany. Both have a department that is named "Sales". And then the "Sales" department is connected to multiple customers. The main objects here are marked in bold.
So here are my objects/nodes in Neo4j: In red the company, blue for customers and green for the offices and yellow for departments. I created three dummy customers here.
Please bare with me - I oversimplify the case here a little bit for the sake of the length and complexity of the post.
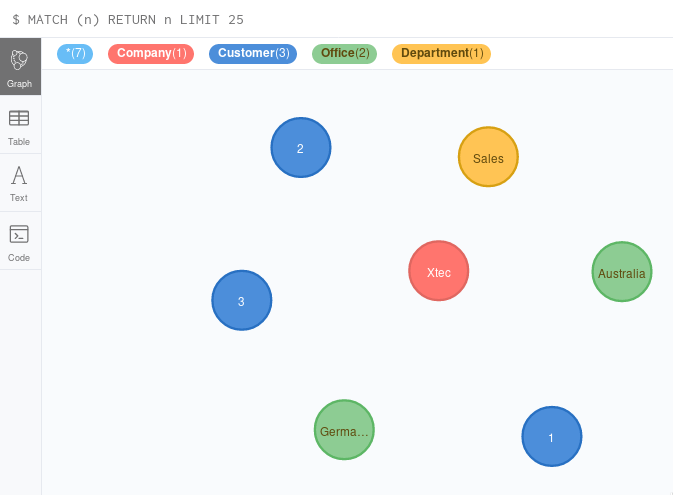
It is important to define and name the main objects. Compared to a relation database - which is a technical representation of the real world - the nodes and relations in a graph represent the real world.
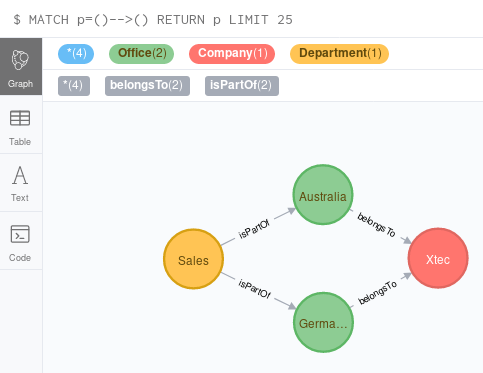
Here is the graph to it. I connected company and offices.
Here is the graph to it. I connected company and offices.
Next I connect offices and departments. So the graph looks now like this:
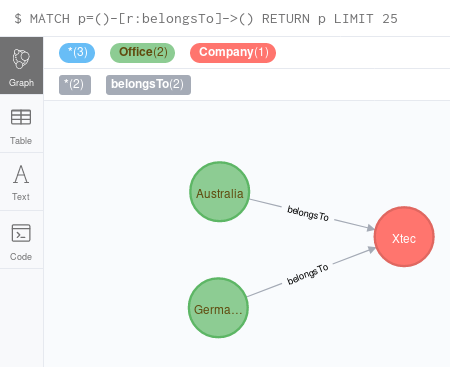
Ok. This is not what I wanted. Both offices connect to the same department. If you think that you connect the customers to the sales department, then how are you going to know which customer belongs to which department. Implicitly we have really two departments. One at the office in Australia and one in the office in Germany. They are not the same objects - they carry just the same name.
Why did I show this? It is about the uniqueness of objects. Objects that are not the same must be distinguished between each other (at least in this case). Typically you would have a unique identifier - e.g. a unique number. In the relational databases world this is a best practice. And then joins are made using this unique identifiers. It assures uniqueness but also helps speed up, as joins on numeric values are more efficient as e.g. on strings. And in the graph world you also need a unique identifier to distinguish - like here - between two things having the same name but actually they are different things.
Reusing nodes in Neo4j happens quickly, when you use "merge". Depending on which attributes you use, you either create a new node or re-use an existing one.
Ideally - in the source data - you have a unique identifier. So when you create the nodes, then you specify the unique identifier as an attribute. Likewise, if you connect the node to others, then a match is done on this identifier to retrieve the correct node to establish the relationship.
In other cases, a unique number might not be available. Typically when you are using CSV files: the "interesting" data was exported to CSV but not the unique id's. So how can you ensure uniqueness? In this case we have the sales department in Australia and the sales department in Germany. When we create the department node, we can specify an additional attribute for the office. This will make the departments unique. It is really just the same in the real world. If you speak about the sales, then one would immediately ask: "Where?", if there are multiple offices!
You could just simply create two separate nodes? Yes. But then if you query the graph, you will get both sales departments back as they are not distinguished. This can cause problems - just as an example - when counting.
Here is the cypher code to create the departments. I use a composite key to distingish them:
Why did I show this? It is about the uniqueness of objects. Objects that are not the same must be distinguished between each other (at least in this case). Typically you would have a unique identifier - e.g. a unique number. In the relational databases world this is a best practice. And then joins are made using this unique identifiers. It assures uniqueness but also helps speed up, as joins on numeric values are more efficient as e.g. on strings. And in the graph world you also need a unique identifier to distinguish - like here - between two things having the same name but actually they are different things.
Reusing nodes in Neo4j happens quickly, when you use "merge". Depending on which attributes you use, you either create a new node or re-use an existing one.
Ideally - in the source data - you have a unique identifier. So when you create the nodes, then you specify the unique identifier as an attribute. Likewise, if you connect the node to others, then a match is done on this identifier to retrieve the correct node to establish the relationship.
In other cases, a unique number might not be available. Typically when you are using CSV files: the "interesting" data was exported to CSV but not the unique id's. So how can you ensure uniqueness? In this case we have the sales department in Australia and the sales department in Germany. When we create the department node, we can specify an additional attribute for the office. This will make the departments unique. It is really just the same in the real world. If you speak about the sales, then one would immediately ask: "Where?", if there are multiple offices!
You could just simply create two separate nodes? Yes. But then if you query the graph, you will get both sales departments back as they are not distinguished. This can cause problems - just as an example - when counting.
Here is the cypher code to create the departments. I use a composite key to distingish them:
Cypher
And this is what the graph looks like now:
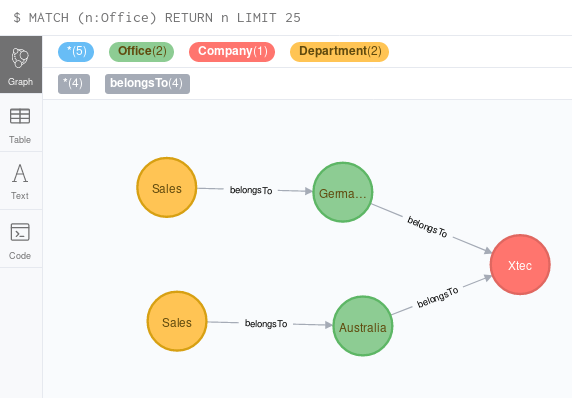
We can now connect the customers to the relevant by specifying which sales department is meant.
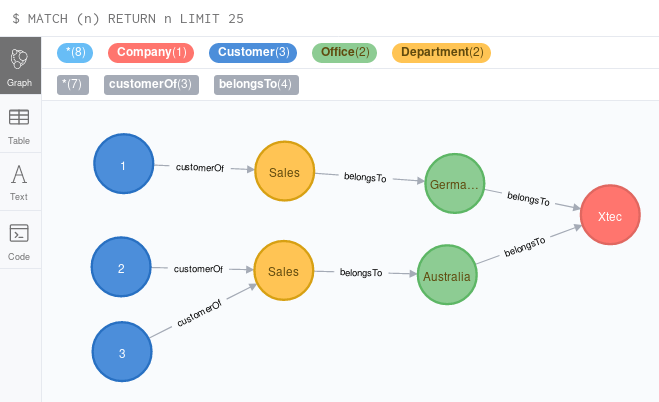
I hope you got the point I was trying to make here: You will find yourself in the position to ask what makes a certain node unique as it will influence your queries but also if your design is logically correct. In other cases you will question the results (number of nodes).
And of course in other cases you would want to share nodes. But this needs a deliberate decision when the graph is designed and the nodes are created. Dependant on the use case there might be multiple ways how one could design the graph.
Let me know your thoughts or how you approach this topic when designing a graph.
Carpe Diem
And of course in other cases you would want to share nodes. But this needs a deliberate decision when the graph is designed and the nodes are created. Dependant on the use case there might be multiple ways how one could design the graph.
Let me know your thoughts or how you approach this topic when designing a graph.
Carpe Diem
 RSS Feed
RSS Feed
