
A short follow up on the last post. Sometimes a picture explains more than 1000 words, so I have visualized the advantages of metadata injection.
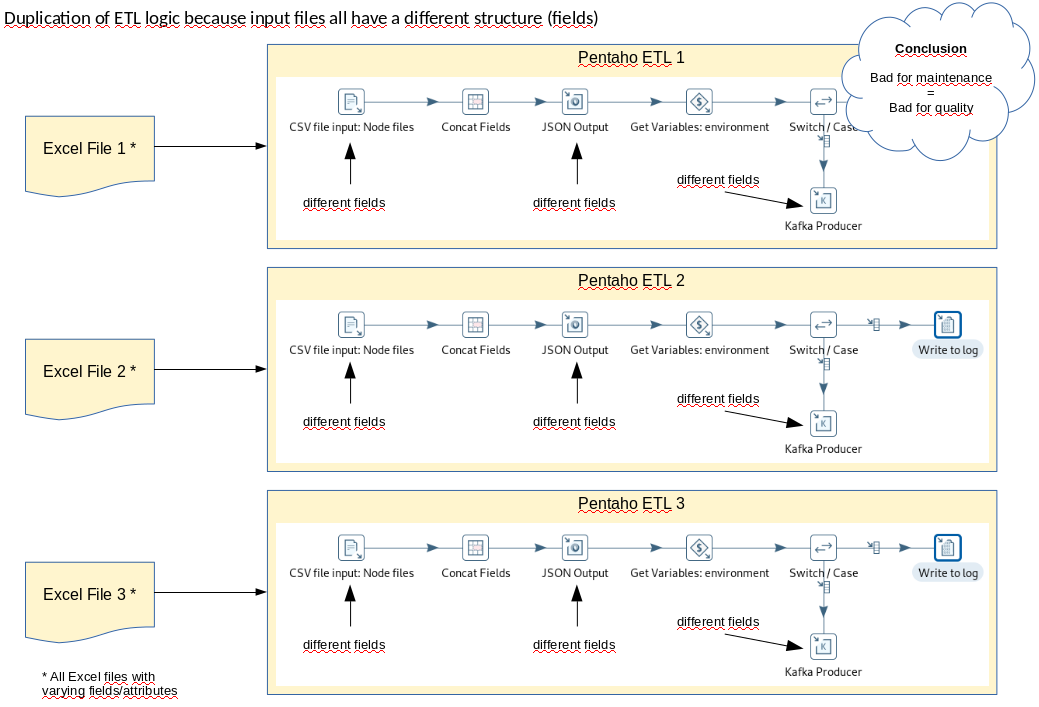
In the screenshot below one can see that with different input files - because they are different e.g. in the fields and data types, the separator used or maybe the encoding - the ETL logic is duplicated. Allthough the same basic logic applies, we need to create multiple transformations because of the file differences.
The result is, that if something changes or the transformation is extended, it has to be done in multiple places. Or if you get additional input files with yet another structure, then you have even more duplication. All this has a bad influence on agility and also quality.
Of course, you could make an effort to generalize some of the logic that all have in common. In this case you would not have multiple (or as many) duplicates. But it makes the overall ETL more complicated because you have things that are different and things that are common. With a growing number of input files (differences) this also gets quickly complicated or even unmanagable.
In the screenshot below one can see that with different input files - because they are different e.g. in the fields and data types, the separator used or maybe the encoding - the ETL logic is duplicated. Allthough the same basic logic applies, we need to create multiple transformations because of the file differences.
The result is, that if something changes or the transformation is extended, it has to be done in multiple places. Or if you get additional input files with yet another structure, then you have even more duplication. All this has a bad influence on agility and also quality.
Of course, you could make an effort to generalize some of the logic that all have in common. In this case you would not have multiple (or as many) duplicates. But it makes the overall ETL more complicated because you have things that are different and things that are common. With a growing number of input files (differences) this also gets quickly complicated or even unmanagable.
If you use metadata injection, then the work to analyze the differences of the input files still has to be done. But the positive aspect is, that you can reduce the number of transformations. Instead you define metadata - e.g. in simple CSV files. This approach is much cleaner and simpler. Simplicity is always good when it comes to maintenance, when you share your development work with others, but also for agility and also the overall quality will benefit.
In this case, when you get additional input files yet in different formates and with different data types, you won't have to touch your ETL logic. You simply define the metadata according to the input file(s) and you are done. So the more different files you have the more you will benefit from this solution.
In this case, when you get additional input files yet in different formates and with different data types, you won't have to touch your ETL logic. You simply define the metadata according to the input file(s) and you are done. So the more different files you have the more you will benefit from this solution.
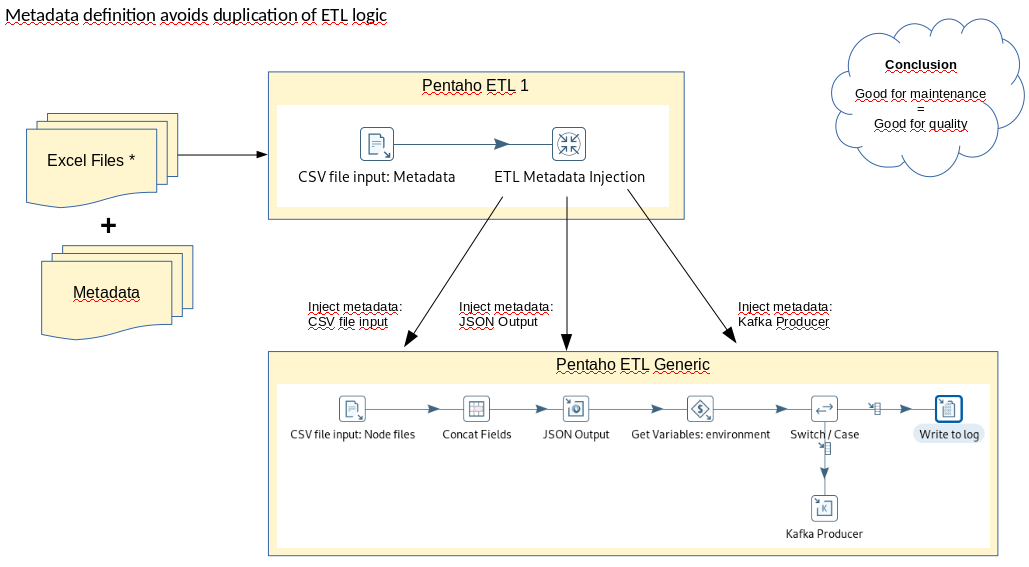
In Pentaho PDI (ETL) metadata injection is available for many of the steps (plugins). Once you have understood the concept and have done it 2 or 3 times, it will be an easy task to use it instead of hardcoding file structure and duplicating logic. Of course, only if metadata injection makes sense in your use case.
Carpe Diem
Carpe Diem
 RSS Feed
RSS Feed
