
I have recently started to use Apache Ignite. And while I am learning, I wanted to see how Pentaho PDI - Pentaho Data Integration - works together with Ignite.
Apache Ignite is - from their website - an "In Memory Computing Platform". The project has a lot of traction and offers interesting features and besides other things, you can use it as a database and query using standard SQL.
Apache Ignite is very easy to install: download Ignite from here and unzip it to a folder of your choice. On the website of Apache Ignite there is a lot of documentation available, if you need help to get started.
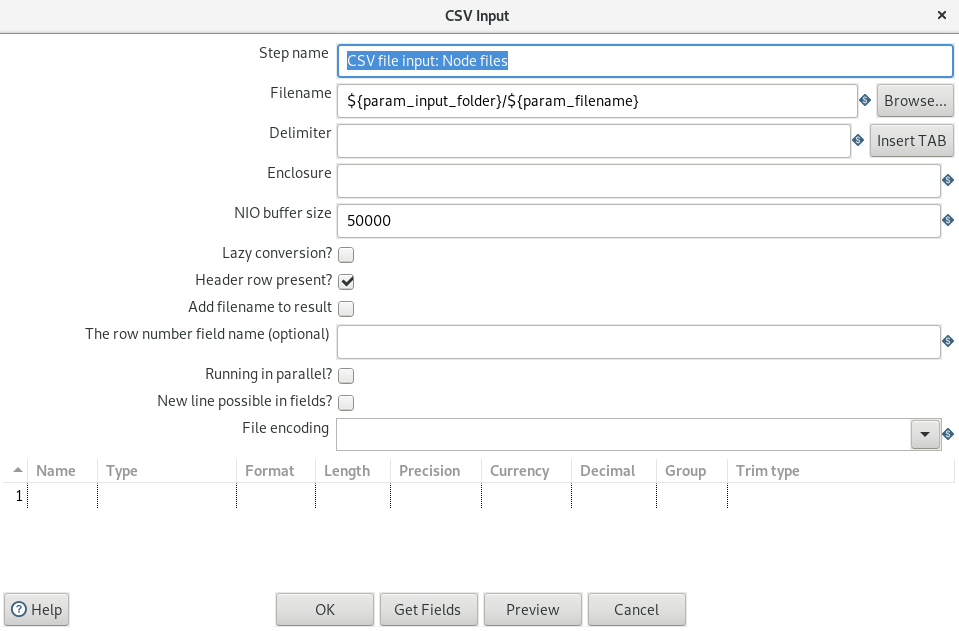
Once unzipped, copy the file "ignite-core-<version>.jar" from the Ignite "libs" folder to the Pentaho PDI folder "lib". This jar file contains the Ignite JDBC driver.
Next, you could start Apache Ignite by running ignite.sh in the "bin" folder. Starting it like this, Ignite will run in a default configuration. All your data will be kept in memory and if you shutdown, all data will be lost. Of course Ignite allows you also to persist data - you can read in the Ignite documentation how to configure this.
But for this discussion, I want to have my data structures (tables) and data in memory only. The idea is to use Ignite to transform data in memory without using any disk-based storage for intermediately storing results, so that the data can be processed faster.
A common approach to transforming data is to first copy data from the source system to a staging area where it can be processed without interfering with the source system. So any development or repeated processing of the data will be done on the data in the staging area. Again, this makes development and testing easier and at the same time the source system is not penetrated by repetatively pulling data from it. The next step is typically transforming the data: applying certain logic, formatting and enriching and joining it with other data. And then the final step would be to output the data to a target system - maybe another database, a data warehouse or a file - there many output targets possible.
Of course it depends on the complexity of the transformation and there are obviously many ways of how to do it. If a transformation is complex, then it naturally makes sense to break it appart in different units of work, where each part has a certain task in the transformation of the data. Like in coding where spaghetti code gets unmanageble over time and is is broken apart into classes, methods and functions.
When you have multiple transformation steps, then the question is, how are the intermediate results of each step stored and passed to the next step? One way can be to store the temporary results in a database. That is convenient and Pentaho PDI has a good database integration. Also, there are many tools available to work with databases. When you run the complete transformation and the individual parts store their data in different database tables, then the developer has an easy way to query the data and see how the transformation progressed and transformed the data.
But repeatedly reading and writing data to a database also has limitations. On large data this can get slow - either on reading or wrting or deleting data. Creating the right indexes and tuning the database can be a complex tasks and there are dependencies on e.g. the disk performance of the database system.
Looking at the transformation process described above, one can see, that the transformation is just an intermediate step to process the source data to a desired output format. Once the result is produced, the intermediate data is not necessary anymore - it can be deleted. Maybe this transformation process runs on a daily basis and so the next day a new state of the source system data is retrieved and the transformation process it to the desired output again.
And if the intermediate data can be deleted then the question is, if we can leverage an in-memory store to avoid using disks and simply do the processing in memory. So this is where I got interested in Apache Ignite. At it's core it is a key/value store but it provides also SQL integration. If you have a lot of transformations which use a database for the staging of the data, but if performance is an issue, then you would not want to redsign all your transformations. With Apache Ignite you could simply change the place where the transformation is writing to and reading from. That is an easy task and it will immediately bring a performance boost processing the data in memory only. And yes, you could of course scale your traditional database as well or tune other parts. Again, there are many ways to do it.
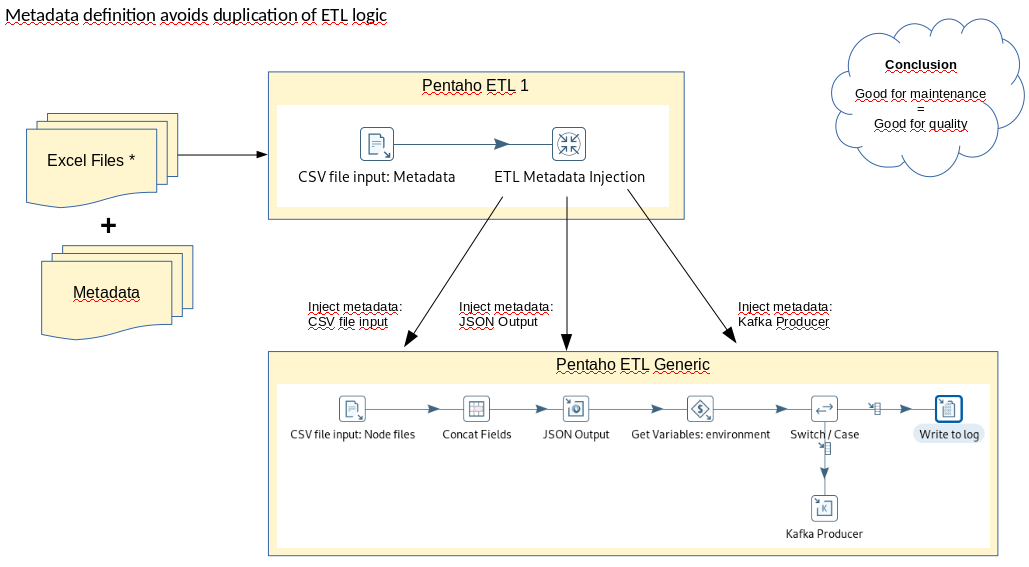
Here is a sample PDI job using Apache Ignite "in the middle" between source system and target system. My source system in this case are several CSV files. The target system is a MySQL database. The processing is done using Apache Ignite.
Apache Ignite is - from their website - an "In Memory Computing Platform". The project has a lot of traction and offers interesting features and besides other things, you can use it as a database and query using standard SQL.
Apache Ignite is very easy to install: download Ignite from here and unzip it to a folder of your choice. On the website of Apache Ignite there is a lot of documentation available, if you need help to get started.
Once unzipped, copy the file "ignite-core-<version>.jar" from the Ignite "libs" folder to the Pentaho PDI folder "lib". This jar file contains the Ignite JDBC driver.
Next, you could start Apache Ignite by running ignite.sh in the "bin" folder. Starting it like this, Ignite will run in a default configuration. All your data will be kept in memory and if you shutdown, all data will be lost. Of course Ignite allows you also to persist data - you can read in the Ignite documentation how to configure this.
But for this discussion, I want to have my data structures (tables) and data in memory only. The idea is to use Ignite to transform data in memory without using any disk-based storage for intermediately storing results, so that the data can be processed faster.
A common approach to transforming data is to first copy data from the source system to a staging area where it can be processed without interfering with the source system. So any development or repeated processing of the data will be done on the data in the staging area. Again, this makes development and testing easier and at the same time the source system is not penetrated by repetatively pulling data from it. The next step is typically transforming the data: applying certain logic, formatting and enriching and joining it with other data. And then the final step would be to output the data to a target system - maybe another database, a data warehouse or a file - there many output targets possible.
Of course it depends on the complexity of the transformation and there are obviously many ways of how to do it. If a transformation is complex, then it naturally makes sense to break it appart in different units of work, where each part has a certain task in the transformation of the data. Like in coding where spaghetti code gets unmanageble over time and is is broken apart into classes, methods and functions.
When you have multiple transformation steps, then the question is, how are the intermediate results of each step stored and passed to the next step? One way can be to store the temporary results in a database. That is convenient and Pentaho PDI has a good database integration. Also, there are many tools available to work with databases. When you run the complete transformation and the individual parts store their data in different database tables, then the developer has an easy way to query the data and see how the transformation progressed and transformed the data.
But repeatedly reading and writing data to a database also has limitations. On large data this can get slow - either on reading or wrting or deleting data. Creating the right indexes and tuning the database can be a complex tasks and there are dependencies on e.g. the disk performance of the database system.
Looking at the transformation process described above, one can see, that the transformation is just an intermediate step to process the source data to a desired output format. Once the result is produced, the intermediate data is not necessary anymore - it can be deleted. Maybe this transformation process runs on a daily basis and so the next day a new state of the source system data is retrieved and the transformation process it to the desired output again.
And if the intermediate data can be deleted then the question is, if we can leverage an in-memory store to avoid using disks and simply do the processing in memory. So this is where I got interested in Apache Ignite. At it's core it is a key/value store but it provides also SQL integration. If you have a lot of transformations which use a database for the staging of the data, but if performance is an issue, then you would not want to redsign all your transformations. With Apache Ignite you could simply change the place where the transformation is writing to and reading from. That is an easy task and it will immediately bring a performance boost processing the data in memory only. And yes, you could of course scale your traditional database as well or tune other parts. Again, there are many ways to do it.
Here is a sample PDI job using Apache Ignite "in the middle" between source system and target system. My source system in this case are several CSV files. The target system is a MySQL database. The processing is done using Apache Ignite.
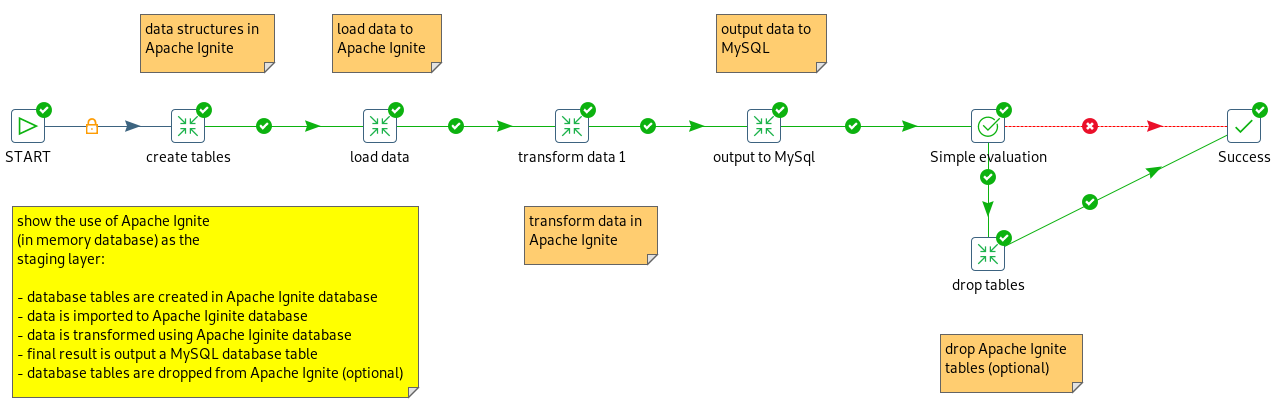
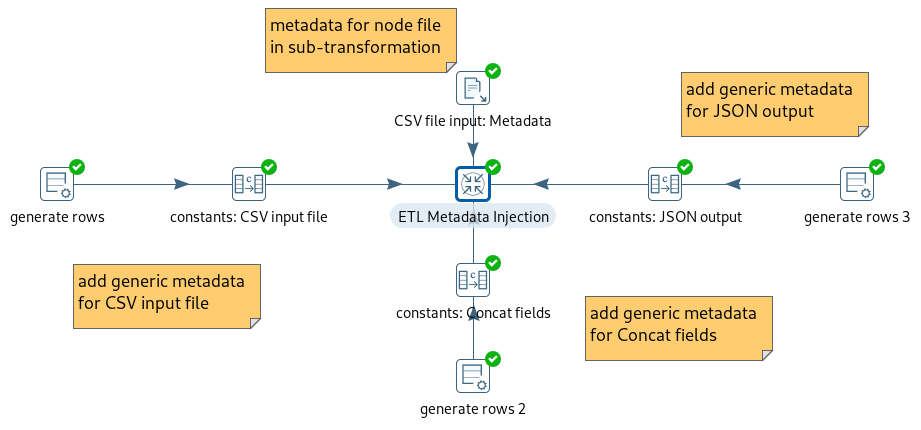
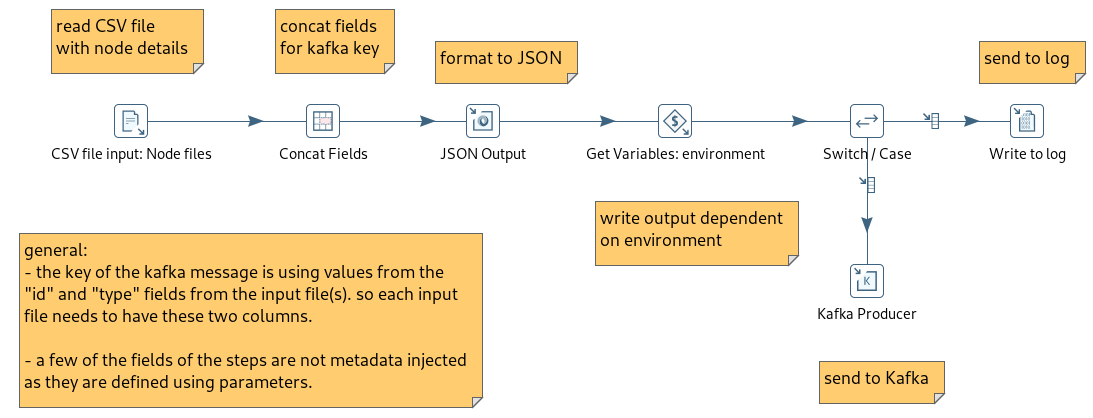
Because Ignite will run in memory - and I have no disk persistence configured in this case - I have chosen to create the required table structures in Ignite at the beginning. Next the data is imported into Ignite and then the data is transformed. Finally the output to MySQL is done. I have an option in this flow to drop the Ignite tables at the end of the process, if that is desired.
As this posts is already long, I stop here. If you are interested in details then read the upcomming follow-up blog entry. I have also some comments of what does not work so nicely between PDI and Ignite at the moment.
Here is the link to part 2.
Carpe Diem
As this posts is already long, I stop here. If you are interested in details then read the upcomming follow-up blog entry. I have also some comments of what does not work so nicely between PDI and Ignite at the moment.
Here is the link to part 2.
Carpe Diem

 RSS Feed
RSS Feed
