
Kafka is a great platform for storing and handling realtime data. Once you have your data in Kafka there is a multitude of ways how to process and work with it.
Now we all know, that the data is often in a shape that it needs further massaging for other downstream processes. If data is adjusted (quality!) or completed early in the flow, then multiple downstream processes can benefit from it. This can be done e.g. using KSQL or by using the streams API - just to name these two.
But hardcoding business or processing logic either in (K)SQL statements or in your code has some disadvantages:
- there is no central place where somebody (developers or business people) can look it up or do central maintenance: this often ends up in duplication of logic.
- it is difficult to understand and overview the business logic, if it is spread all over the place: that is a time consuming and quality issue.
- the logic is maintained by a KSQL or coding specialist - by IT: IT does all the work...
- business users have no clue if you try to explain the logic in your code, e.g. to find errors or discuss changes: it is intransparent to the business
- there is no proper separation of responsibilities between the business users and IT: the business users - the experts for their domain - should really be the ones to maintain the business logic
- code in any form that contains business logic is difficult to maintain. It clutters the code and thus slows down maintenance and development in general. Removing the logic from the code will make the process more agile and clear code is a definite plus for quality.
I have written a ruleengine in Java. It is already in production at least in two bigger companies that I know of. There is also a plugin available for the Pentaho PDI (Data Integration/ETL) tool. And there is a processor available for Apache Nifi.
But the ruleengine is also a good fit for Kafka. What does the ruleengine do? It allows to execute logic against data. Based on the results of the execution one can decide how to further process the data - data either passes or fails the applied logic. The ruleengine gives you tremendous flexibility to construct (complex) logic.
There is a web interface available to do the central maintenance of the logic. The logic is maintained in projects that collect the logic for a certain purpose. It comes with features such as user access, search, history of changes, copy functions and more. Groups of rules - building a certain logic - have a validity date and can have dependencies on other rule groups.
The ruleengine addresses all the disadvantages listed above: a plus for centralizing rule and business logic, separating IT and business responsibilites and making the logic more transparent.
Now how can this be used in Kafka? I am showing two scenarios here which the ruleengine can be used for. There are others, but I focus this time on these two:
- Adjust or modify the data from a Kafka source topic: data is corrected or supplemented and output to a target topic
- Adjust or modify the data from a Kafka source topic and route the failed and passed data to different target topics: the data is devided into "failed" and "passed" or "correct" and "incorrect"
In both cases - and I think it is a very cool feature - there is also the possibility to output the detailed results of the execution of the business logic to another topic. The detailed results show the results of each rule that ran and why it failed. It is a sort of logging of the quality of the data.
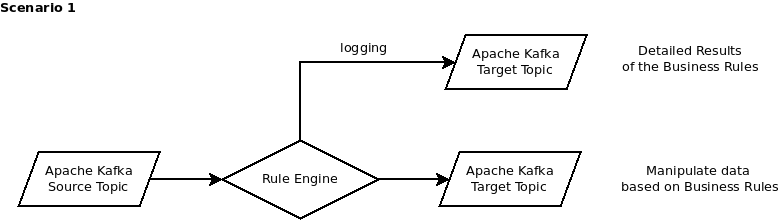
Scenario 1:
Data is read from a Kafka topic, it runs through the ruleengine and it applies the logic to the data. The data is then paased onwards to the target topic. Data is checked and subsequently can be modified based on the results of the check. Also new data (fields) can be created to supplement the data: e.g. based on the content of one field a value for a second field is set. One can concat field values, do calculations, lookup from a map and much more.
As indicated above, the detailed results of running the rules against the data may be output to a separate topic and thus you have an explanation why certain updates where made and others not. It allows to detect errors in the data, with explanations why a record passed or failed. A trail of the decisions if you want to.
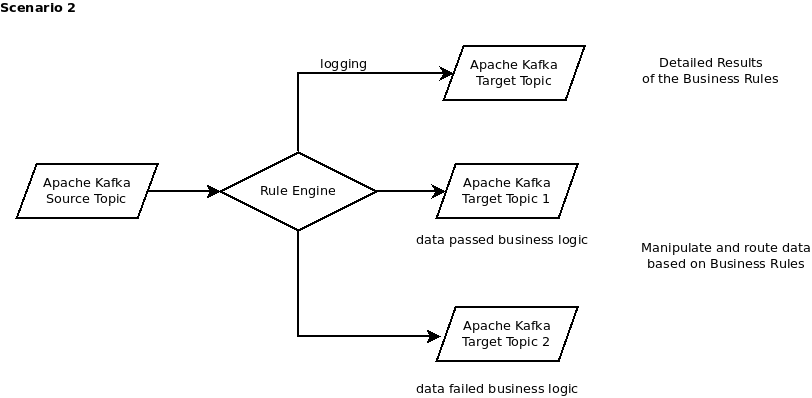
Scenario 2:
Similar to the first scenario but here the passed and failed data (records) are separated into different topics, based on the results of running the rules. What is passed or failed can be based on very complex logic.
Similar to the first scenario but here the passed and failed data (records) are separated into different topics, based on the results of running the rules. What is passed or failed can be based on very complex logic.
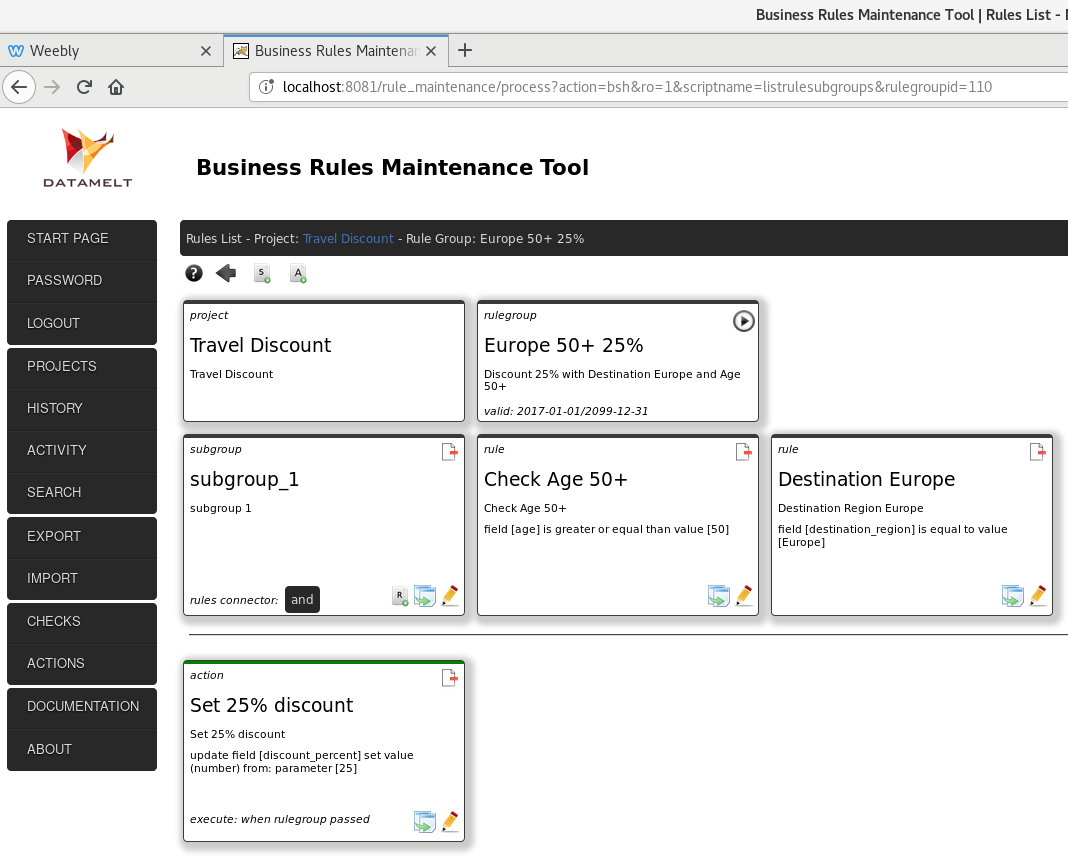
And here is a screenshot of the web based tool for the central maintenance of the business logic. It is a (business) user friendly way to construct logic for multiple purposes. Actually it is of course not limited to Kafka or the other tools I mentioned. It can be used in any Java related project, be it web based or an application.
Massaging data from incomplete sources or from systems with data quality issues is a task we all know. Often, the sources can not be changed. Applying logic to standardize, enhance or complete data and doing it in a centralzed approach enhances quality and transparency. It also relieves our code or processes from clutter and thus makes it more agile for changes.
This all is freely available under the Apache license: the ruleengine and the web tool. Also the Pentaho ETL plugin and the Nifi processor.
If this al makes sense to you then stay online for the second part, where I will show some samples and more details of how to use the ruleengine with kafka and how things come together.
I will upload the code soon to Github. If you want to check out my other projects please visit: https://github.com/uwegeercken.
Carpe Diem
This all is freely available under the Apache license: the ruleengine and the web tool. Also the Pentaho ETL plugin and the Nifi processor.
If this al makes sense to you then stay online for the second part, where I will show some samples and more details of how to use the ruleengine with kafka and how things come together.
I will upload the code soon to Github. If you want to check out my other projects please visit: https://github.com/uwegeercken.
Carpe Diem
 RSS Feed
RSS Feed
