
Welcome to part two. I have been experimenting quite a lot in the last time combining Pentaho PDI (Kettle) - the Pentaho ETL tool - with Neo4j. One thing obvious is, that when you have more than a couple of nodes and relationships to create and you do it from e.g. CSV files, then you quickly start to duplicate a lot of things - e.g. reading the file and outputting it to Neo4j.
Metadata Injection:
But there is a way around this duplication: PDI - as the great ETL tool it is - supports metadata injection. So instead of hardcoding field names, data types and various other things, these can be injected to a step at runtime. So when you have different CSV files for different nodes - because they have different attributes and data types - then you can define this metadata (e.g. in a file). When a node shall be created, the relevant metadata is then used at runtime to fill the PDI steps and with the next node, exactly the same is done. This avoids the duplication I talked about previously.
Actually many steps in PDI support metadata injection. Not only for fields and data types, but also for filenames, formatting (separators, enclsure), encoding (UTF-8) and much more.
The plan:
What I plan to do is to use metadata inection in PDI to load data about Neo4j nodes from CSV files into Kafka. And then I will have another process that will consume data from a different Kafka topics (one for each Neo4j node) and create or merge or update the nodes and also the relationships. This I will show in the part 3 of this blog series.
The messages all have an "event_type" attribute. This indicates which type of event (transaction) is applicable: insert, create, merge or delete.
I put it into Kafka for several reasons:
Use Case:
The graph I will create, will store information about source systems, target systems, connectors, servers, clusters, people and much more. So it shows how these individual object are connected to each other and then in turn allow to make queries on it.
So the first step is to read the CSV files for the different nodes and output the data to Kafka - one topic per node type. At the beginning I have defined which nodes I need and their relationships. Then I have created several CSV files which contain a header defining the attributes of the node and then some data.
Here is an example:
Metadata Injection:
But there is a way around this duplication: PDI - as the great ETL tool it is - supports metadata injection. So instead of hardcoding field names, data types and various other things, these can be injected to a step at runtime. So when you have different CSV files for different nodes - because they have different attributes and data types - then you can define this metadata (e.g. in a file). When a node shall be created, the relevant metadata is then used at runtime to fill the PDI steps and with the next node, exactly the same is done. This avoids the duplication I talked about previously.
Actually many steps in PDI support metadata injection. Not only for fields and data types, but also for filenames, formatting (separators, enclsure), encoding (UTF-8) and much more.
The plan:
What I plan to do is to use metadata inection in PDI to load data about Neo4j nodes from CSV files into Kafka. And then I will have another process that will consume data from a different Kafka topics (one for each Neo4j node) and create or merge or update the nodes and also the relationships. This I will show in the part 3 of this blog series.
The messages all have an "event_type" attribute. This indicates which type of event (transaction) is applicable: insert, create, merge or delete.
I put it into Kafka for several reasons:
- I can wipe my graph, reset my Kafka consumer to the beginning of the topic and "replay" all events that happened, which in turn recreates my graph from scratch.
- I can feed Kafka e.g. from a file or do it manually; for the consumer side of the messages nothing will change if I change this end. I could also e.g. hook up a database (with CDC - Change Data Capture) and get the data from there.
- Kafka gives me the realtime processing capabilities. Data that arrives in Kafka as events can immediately be consumed and trigger an update of my graph.
Use Case:
The graph I will create, will store information about source systems, target systems, connectors, servers, clusters, people and much more. So it shows how these individual object are connected to each other and then in turn allow to make queries on it.
So the first step is to read the CSV files for the different nodes and output the data to Kafka - one topic per node type. At the beginning I have defined which nodes I need and their relationships. Then I have created several CSV files which contain a header defining the attributes of the node and then some data.
Here is an example:

The "type" field will be used as the label of the nodes in Neo4j. And the "event_type" is the type of transaction that has to be done. Later the "source_system_id" will be used to create a relation from this node (ITApplicationOwner) to the SourceSystem node.
Then I have a PDI transformation which contains the metadata injection step and several other parts that deliver the metadata to this step. Inside the metadata injection step the mapping is done of metadata to the relevant fields in the steps of another (child) transformation.
This is what the transformation looks like. In the subtransformation there are steps to:
Then I have a PDI transformation which contains the metadata injection step and several other parts that deliver the metadata to this step. Inside the metadata injection step the mapping is done of metadata to the relevant fields in the steps of another (child) transformation.
This is what the transformation looks like. In the subtransformation there are steps to:
- read the relevant CSV file
- concat two fields to construct the key of the Kafka message
- format the data to JSON format
- dependent on the "environment" setting (DEV or PROD) send the result either to the log or to Kafka.
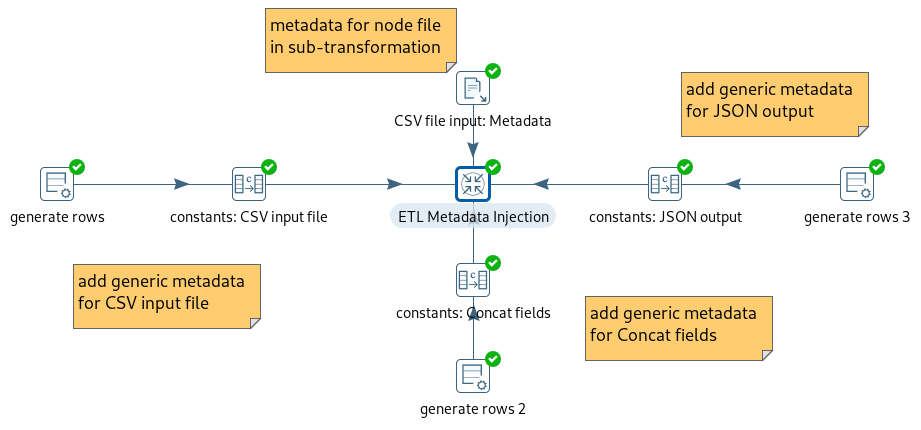
So the steps that run the the metadata injection step in the middle, provide information about which fields are used in the CSV file, which delimiter is used, which encoding and more. For the JSON output step also the fields and data types are required and e.g for the steps that concats the two fields I need to provide the name of the resulting field of the concatenation.
Now the subtransformation:
Now the subtransformation:
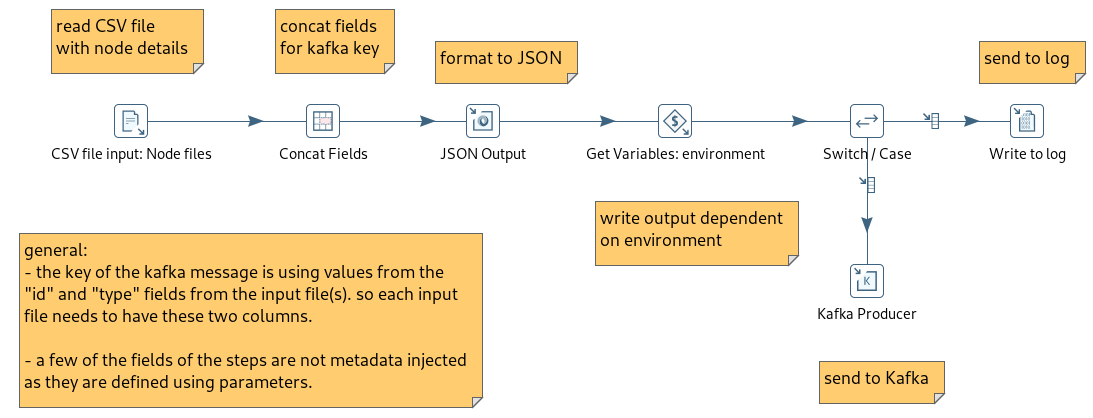
From the metadata injection step, the "CSV file input" step above gets the definition of the fields in the CSV file and also the data types. Next the two fields are concatenated and then the "environment" setting is evaluated and the flow continues to write to the log or send the message to Kafka.
Let's have a look athe "CSV file input" step:
Let's have a look athe "CSV file input" step:
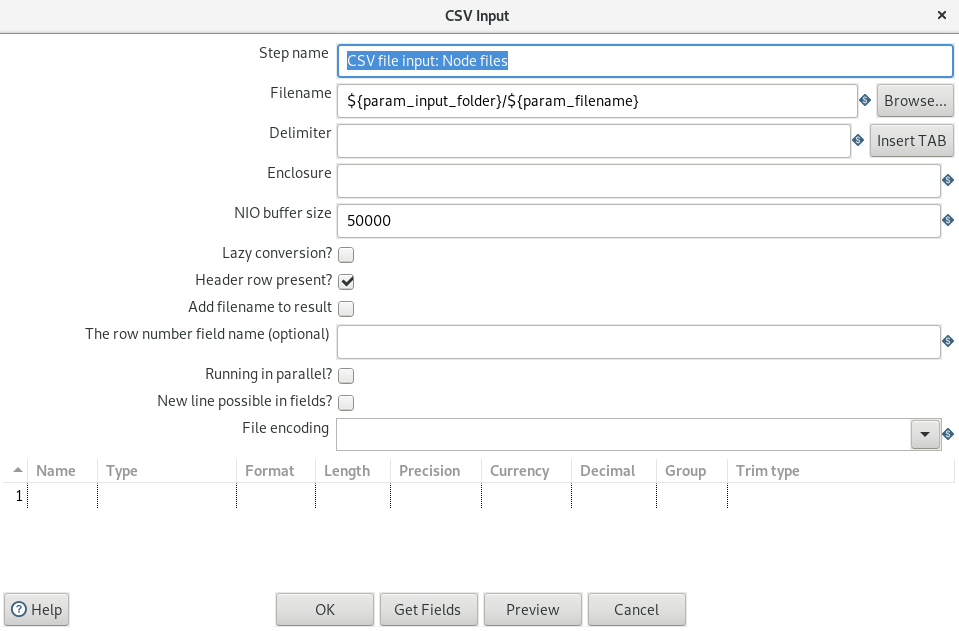
You can see that - at the bottom - there are no fields and data types defined. Usually - in a transformation without metadata injection - one would have to define the fields that the CSV file is made up of. But here it is empty. These settings are injected at runtime into this step. Also the "delimiter, "enclosure" and "File encoding".
For the "ITApplicationOwner" node and CSV file shown futher above, I have defined this metadata file:
For the "ITApplicationOwner" node and CSV file shown futher above, I have defined this metadata file:
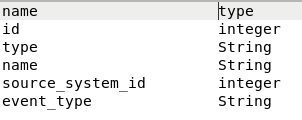
The first line is the header row. The following lines each define a field and the data type and are injected to the step (for the "Name" and "Type" field) shown in the previous screenprint.
And this is what metainjection does: In this case, I only have to define the metadata of each CSV file I want to use. At runtime this structure is injected so that I can have lots of differently formatted files and still just need one flow and logic to process them.
As you can see above, there is also a configuration in the "CSV input file" step for the "Filename" - the file - that shall be processed. This does not come from the metadata. Instead I have defined parameters for that. When I run the whole transformation, then before it kicks off, I specify the file (filename) I want to process and this information will be inserted appropriately. This way - at runtime - I can dynamically load different files. And of course this could be scripted and scheduled to process many files.
Here is the log info for the processed "ITApplicationOwner" CSV file that will later become a node in Neo4j. Below you can see the key and message (in JSON) that would be sent to Kafka:
And this is what metainjection does: In this case, I only have to define the metadata of each CSV file I want to use. At runtime this structure is injected so that I can have lots of differently formatted files and still just need one flow and logic to process them.
As you can see above, there is also a configuration in the "CSV input file" step for the "Filename" - the file - that shall be processed. This does not come from the metadata. Instead I have defined parameters for that. When I run the whole transformation, then before it kicks off, I specify the file (filename) I want to process and this information will be inserted appropriately. This way - at runtime - I can dynamically load different files. And of course this could be scripted and scheduled to process many files.
Here is the log info for the processed "ITApplicationOwner" CSV file that will later become a node in Neo4j. Below you can see the key and message (in JSON) that would be sent to Kafka:
Snippet from logfile
And when I run this exact transformation again, but using a different file (here: "SourceSystem") with different metadata, then this comes out in the log:
Snippet 2 from logfile
As you can see, Pentaho PDI and metadata injection are immensly helpful to avoid duplicate work and hardcoding. And as such it is a clear plus for data quality: easier flows/logic will be easier to control and to maintain.
It is a different way of constructing an ETL, but it is way more efficient than to create several flows and logic e.g. one flow per CSV file and Node type. You end up doing the same things over and over again just with a little bit of difference in the file structure.
Now there is not so much Neo4j in here today, other than I have prepared the data to be sent to Kafka. But then the next part of this series will use also PDI (with metadata injection) to consume the data from kafka and then send it to Neo4j to construct a graph.
It will be a somewhat universal process to allow to update the Neo4j graph based on messages that arrive in Kafka. So a message that is sent to Kafka (from the console or a file or maybe a database) is immediately processed by PDI and updates the graph (database).
As always, send me your comments or questions please. Hope you enjoyed it.
Carpe Diem.
It is a different way of constructing an ETL, but it is way more efficient than to create several flows and logic e.g. one flow per CSV file and Node type. You end up doing the same things over and over again just with a little bit of difference in the file structure.
Now there is not so much Neo4j in here today, other than I have prepared the data to be sent to Kafka. But then the next part of this series will use also PDI (with metadata injection) to consume the data from kafka and then send it to Neo4j to construct a graph.
It will be a somewhat universal process to allow to update the Neo4j graph based on messages that arrive in Kafka. So a message that is sent to Kafka (from the console or a file or maybe a database) is immediately processed by PDI and updates the graph (database).
As always, send me your comments or questions please. Hope you enjoyed it.
Carpe Diem.
 RSS Feed
RSS Feed
