
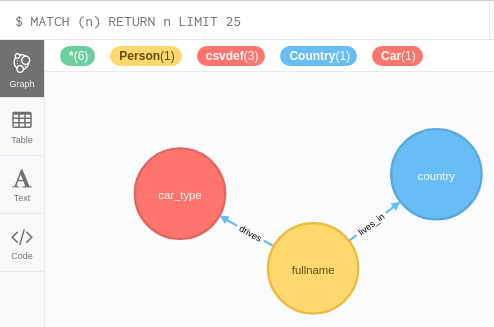
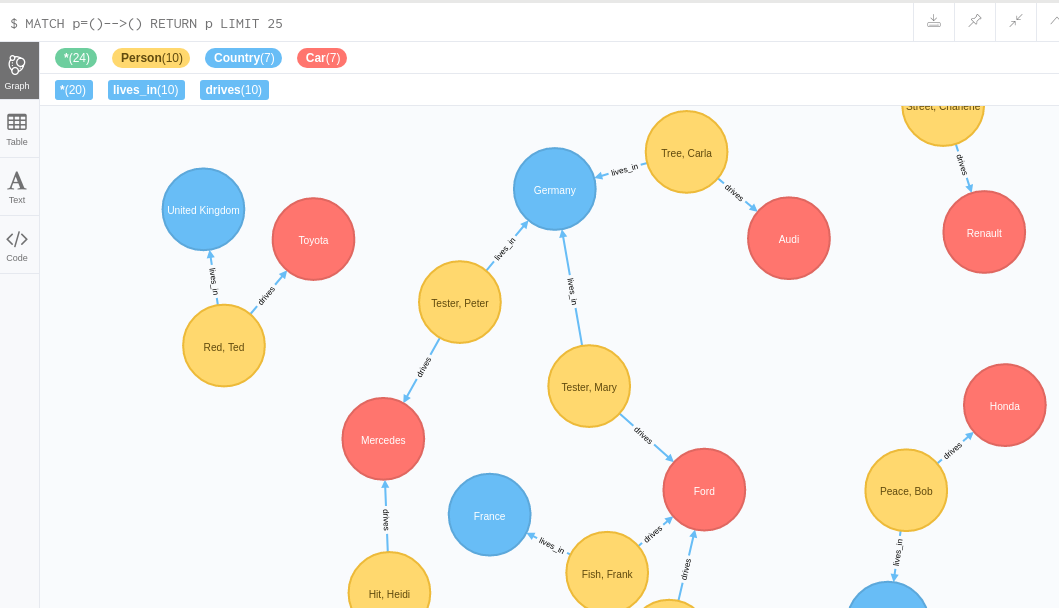
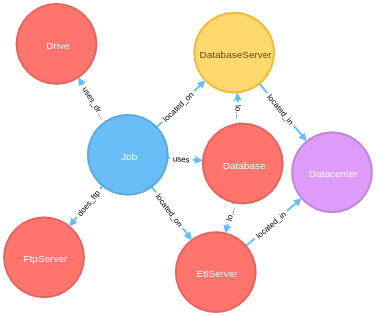
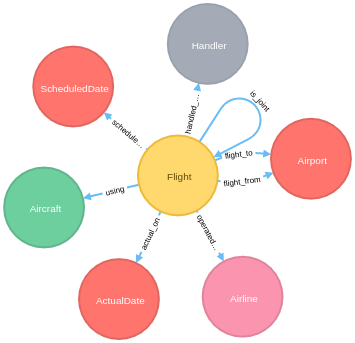
just a quick update: I have improved the performance of processing rows of CSV data significantly. And then I have changed the way how one models the nodes. So the syntax is different and in the end also easier to use.
Check out the readme file on my GitHub account for more details. Download the tool and please send me feedback if you do so.
Carpe Diem
Check out the readme file on my GitHub account for more details. Download the tool and please send me feedback if you do so.
Carpe Diem

 RSS Feed
RSS Feed
