
I finally found some time to test the Neo4j connector to Kafka. Specifically I am showing here how to use the consumer in Neo4j to consume data from Kafka. I have not found a sample on the web, so I thought I show one here.
Information about the connector is available here: github.com/neo4j-contrib/neo4j-streams
Some more documentation is here: neo4j-contrib.github.io/neo4j-streams/
My setup is as follows:
MySQL:
Here are the tables:
Information about the connector is available here: github.com/neo4j-contrib/neo4j-streams
Some more documentation is here: neo4j-contrib.github.io/neo4j-streams/
My setup is as follows:
- MySQL: I have data in a MySQL database containing information about airlines and airports and which airline flies from which origin airport to which destination airport
- Nifi: I use Apache Nifi to listen for changes to the MySQL database tables and to send the data to Kafka
- Neo4j: is configured to consume data from the three topics created using Nifi
MySQL:
Here are the tables:
MySQL Tables
and here the first 10 rows from each table:
MySQL Data
The id column is an autoincrement value and the last_update is the inserted or last updated timestamp for the records in each table. The airlines_airports table has the information of which airline flies from where to where (to which airport).
Nifi:
Updates to the MySQL tables will result in an update of the last_update column of the relevant record. Nifi will pickup the change records and send them to Kafka in JSON format.
My Dataflow looks like this:
Nifi:
Updates to the MySQL tables will result in an update of the last_update column of the relevant record. Nifi will pickup the change records and send them to Kafka in JSON format.
My Dataflow looks like this:
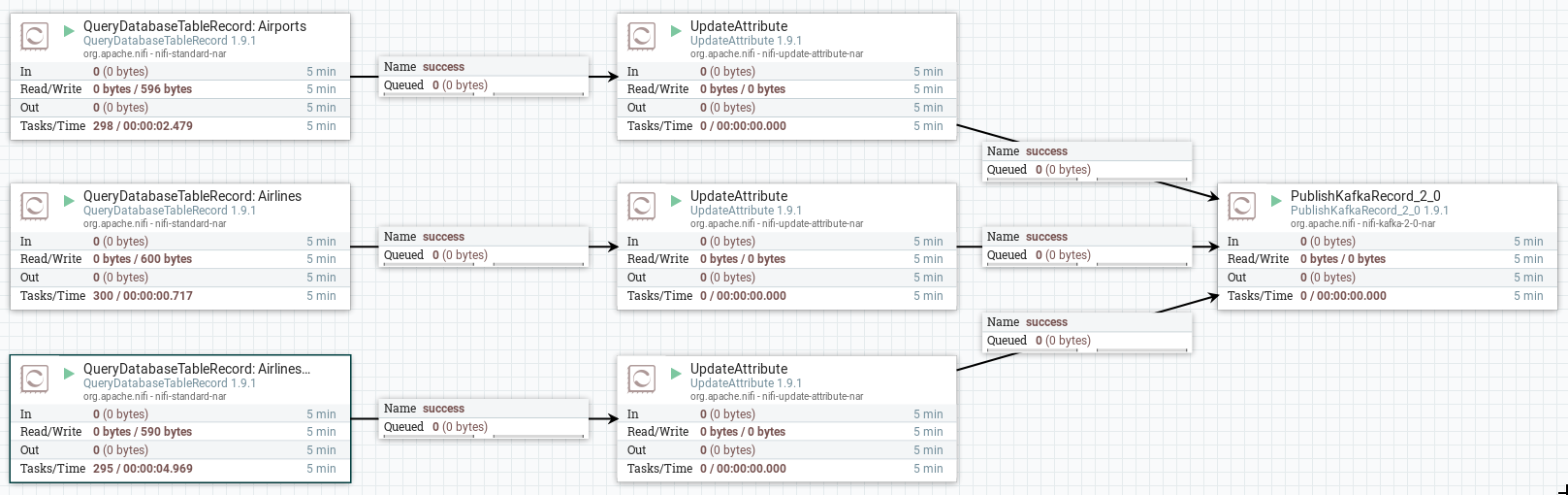
Three QueryDatabaseTableRecord processors are used to watch for changes to the three MySQL tables. The UpdateAttribute processors are used to simply define the name of the Kafka topic. Finally the records are sent to Kafka using the PublishKafkaRecord processor.
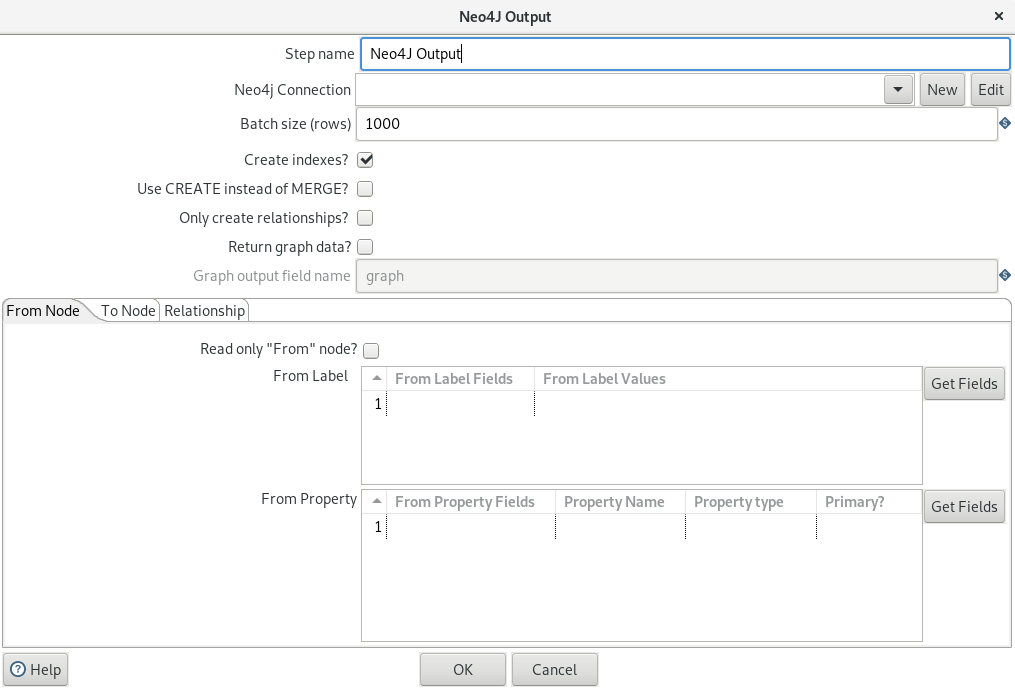
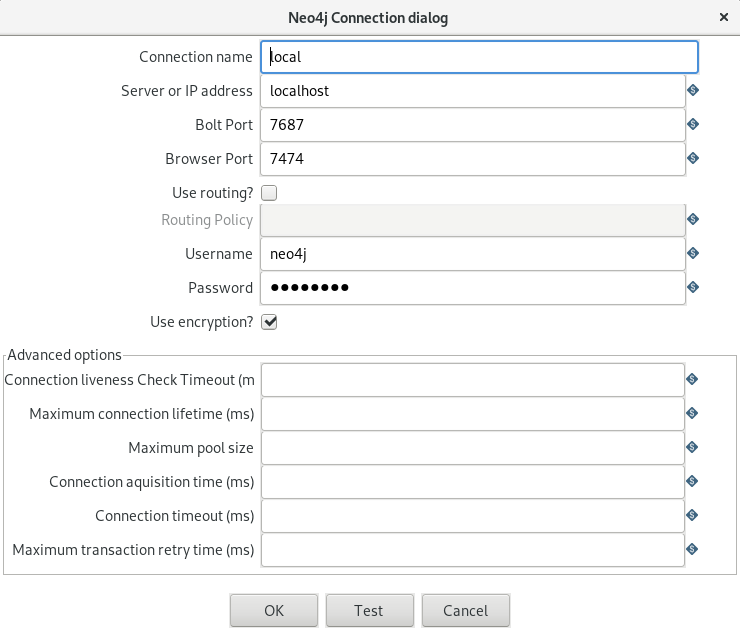
Neo4j:
I have adjusted the Neo4j configuration as documented (see link at the beginning). First, I have added the Kafka config at the end of the neo4j.conf file:
Neo4j:
I have adjusted the Neo4j configuration as documented (see link at the beginning). First, I have added the Kafka config at the end of the neo4j.conf file:
File: neo4j.conf
This is configuration for zookeeper, the Kafka brokers, the consumer group id and some others. After this I added three cypher statements to process data from the three Kafka topics:
Cypher: Airports
Cypher: Airlines
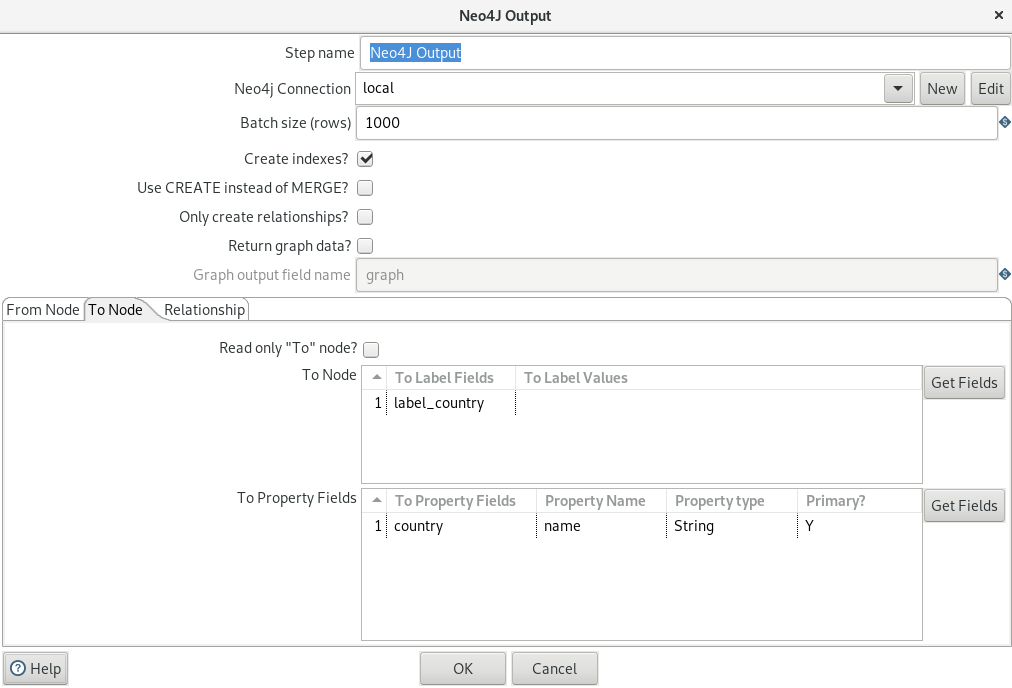
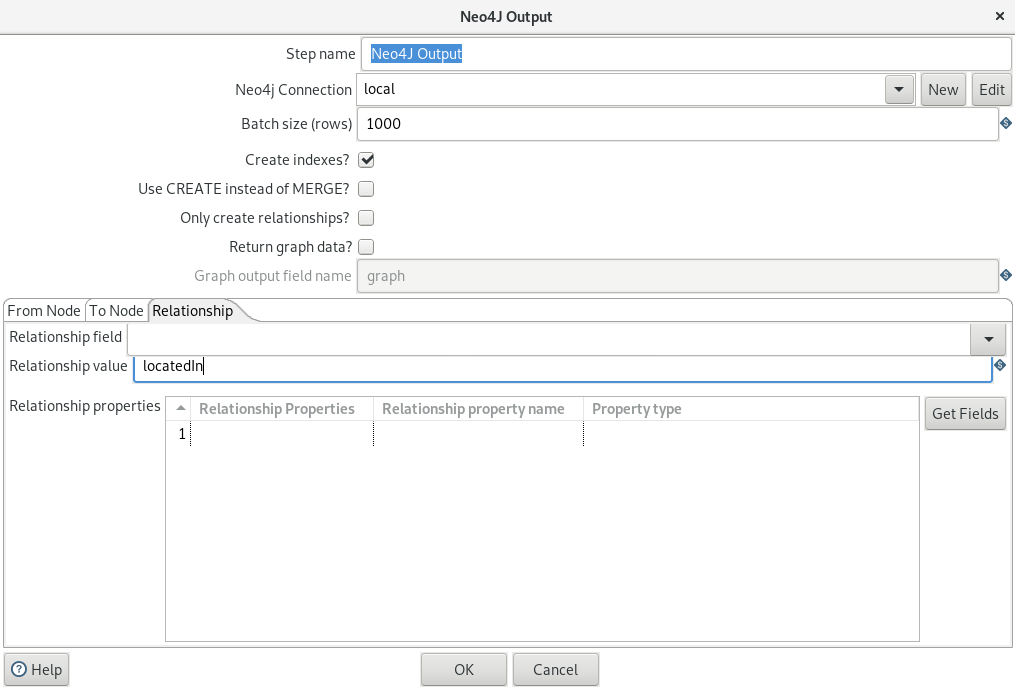
Cypher: Airlines-Airports
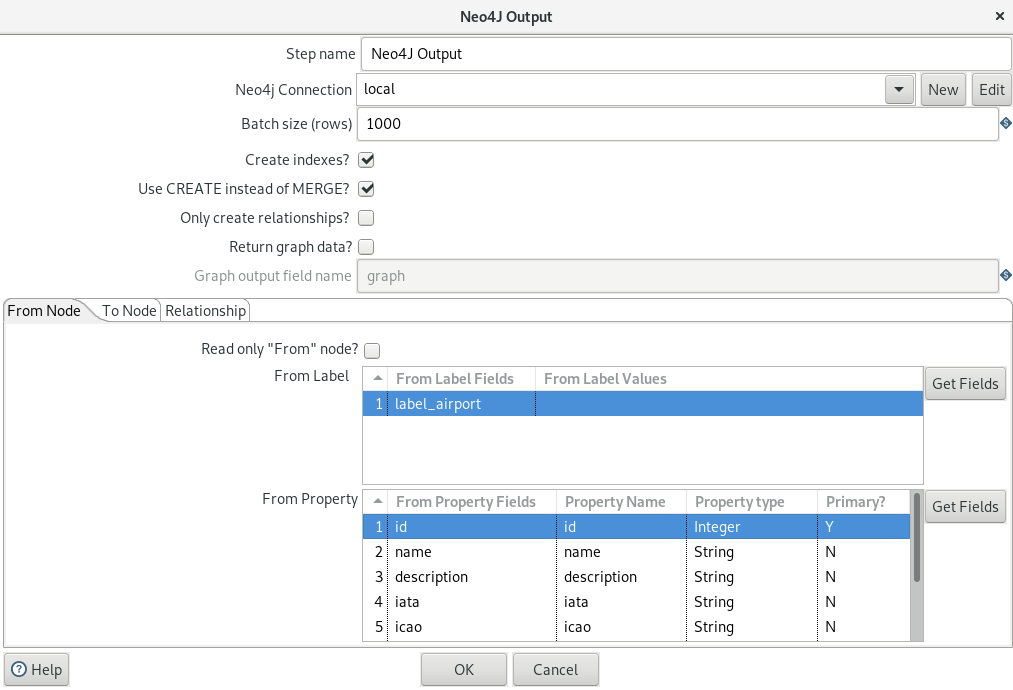
The first two cypher statements do a merge on the Airport or Airline based on the ID of the records. If the relevant ids exist they are updated, otherwise created.
The last cypher statement creates the relationship between the airports and the airlines: which airlines flies from which airport (origin) to which other airport (destination).
So this is my data pipeline: MySQL has the data and any updates are made here. The changes are picked up by Nifi, which send it to the relevant Kafka topic. And because I configured the three cypher statements in the Neo4j config, Neo4j consumes any messages that arrive in the three Kafka topics. And if there are any changes in the MySQL data, then they will automatically arrive in Neo4j.
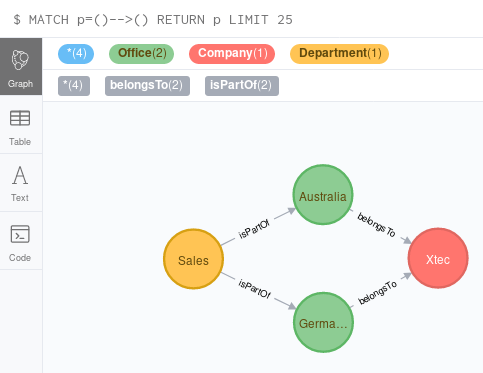
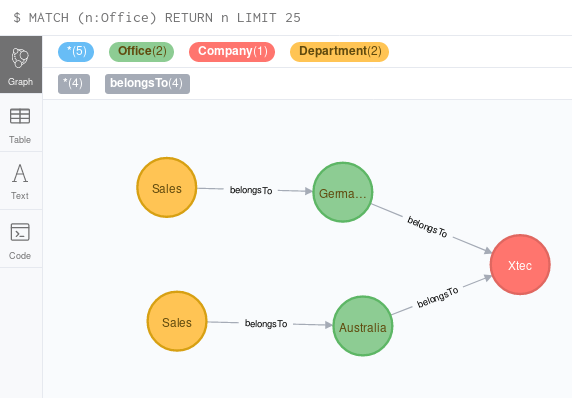
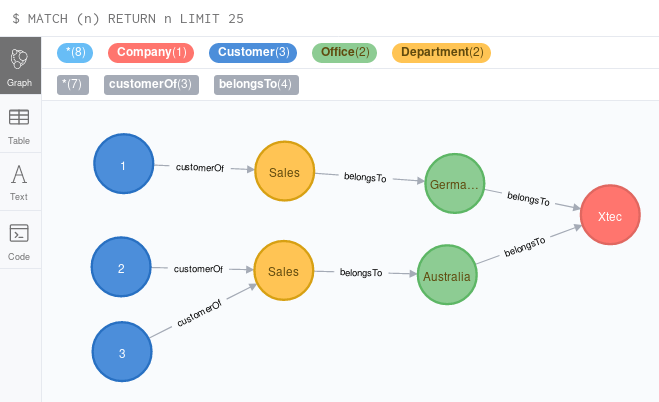
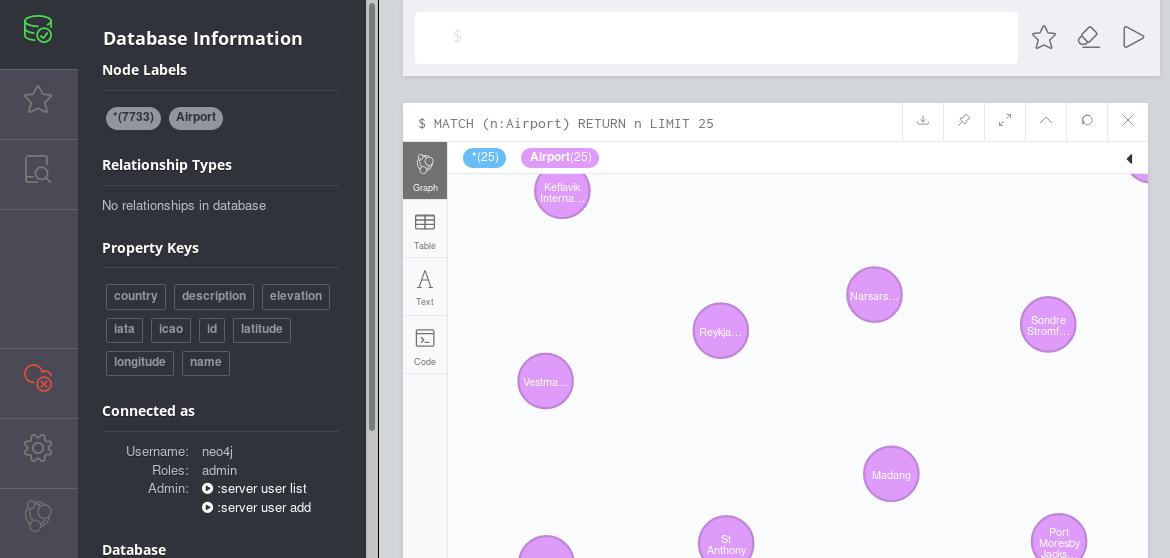
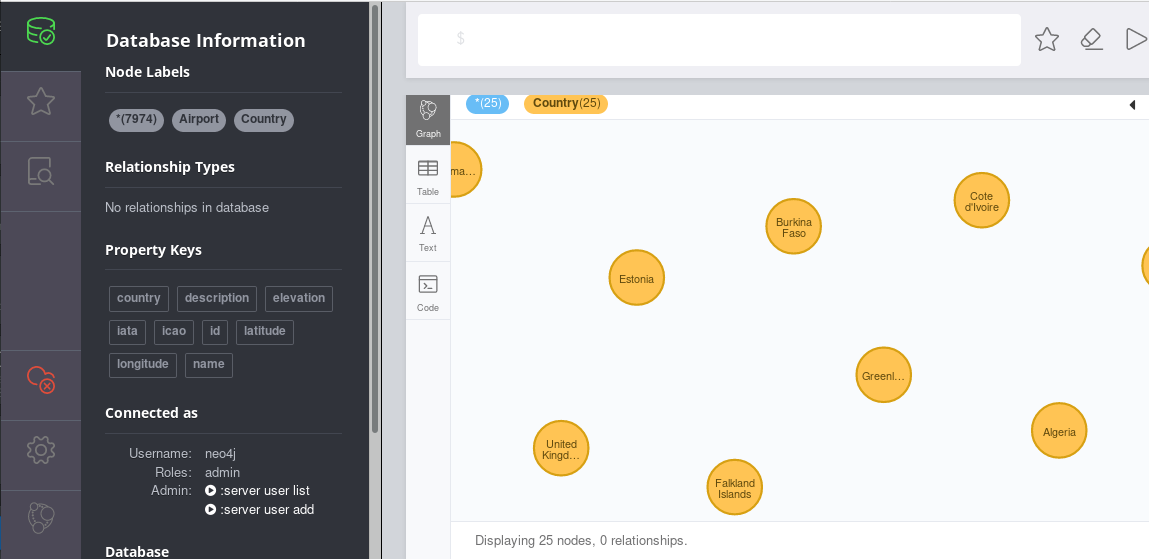
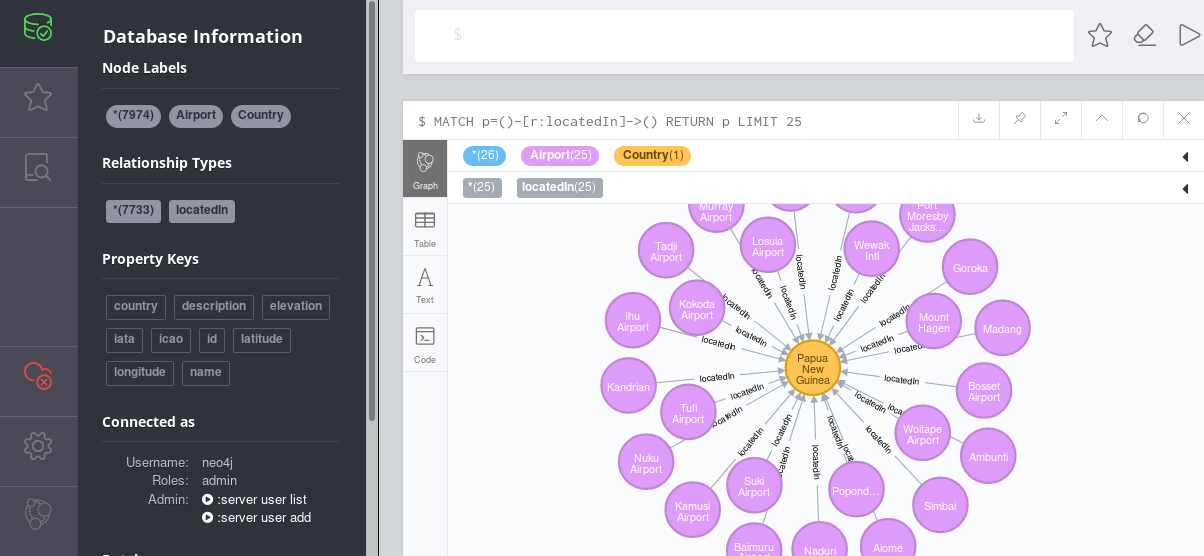
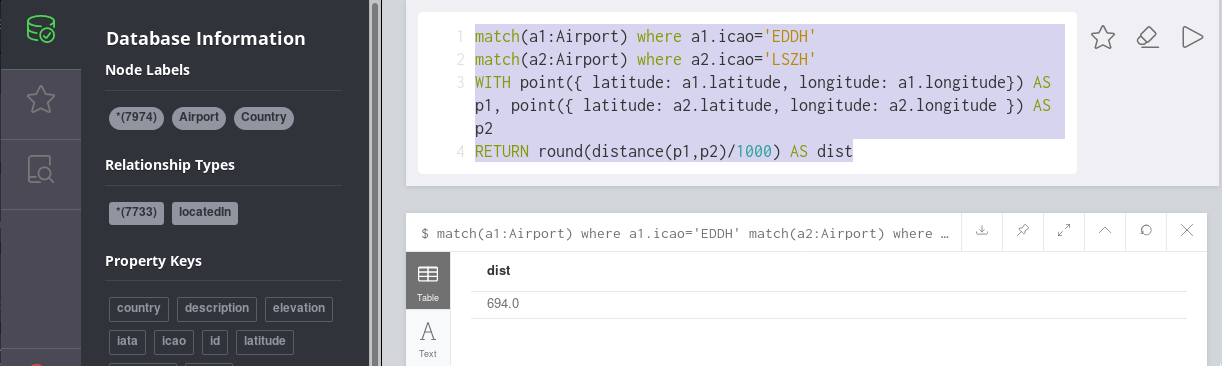
Once the data is available or updated in Neo4j, I can run e.g. a query to see where Swiss (airline code=LX) is flying to from Zurich (airport code=ZRH).
The last cypher statement creates the relationship between the airports and the airlines: which airlines flies from which airport (origin) to which other airport (destination).
So this is my data pipeline: MySQL has the data and any updates are made here. The changes are picked up by Nifi, which send it to the relevant Kafka topic. And because I configured the three cypher statements in the Neo4j config, Neo4j consumes any messages that arrive in the three Kafka topics. And if there are any changes in the MySQL data, then they will automatically arrive in Neo4j.
Once the data is available or updated in Neo4j, I can run e.g. a query to see where Swiss (airline code=LX) is flying to from Zurich (airport code=ZRH).
Cypher: Find destination of Swiss departing from Zurich
The result would then look like this:
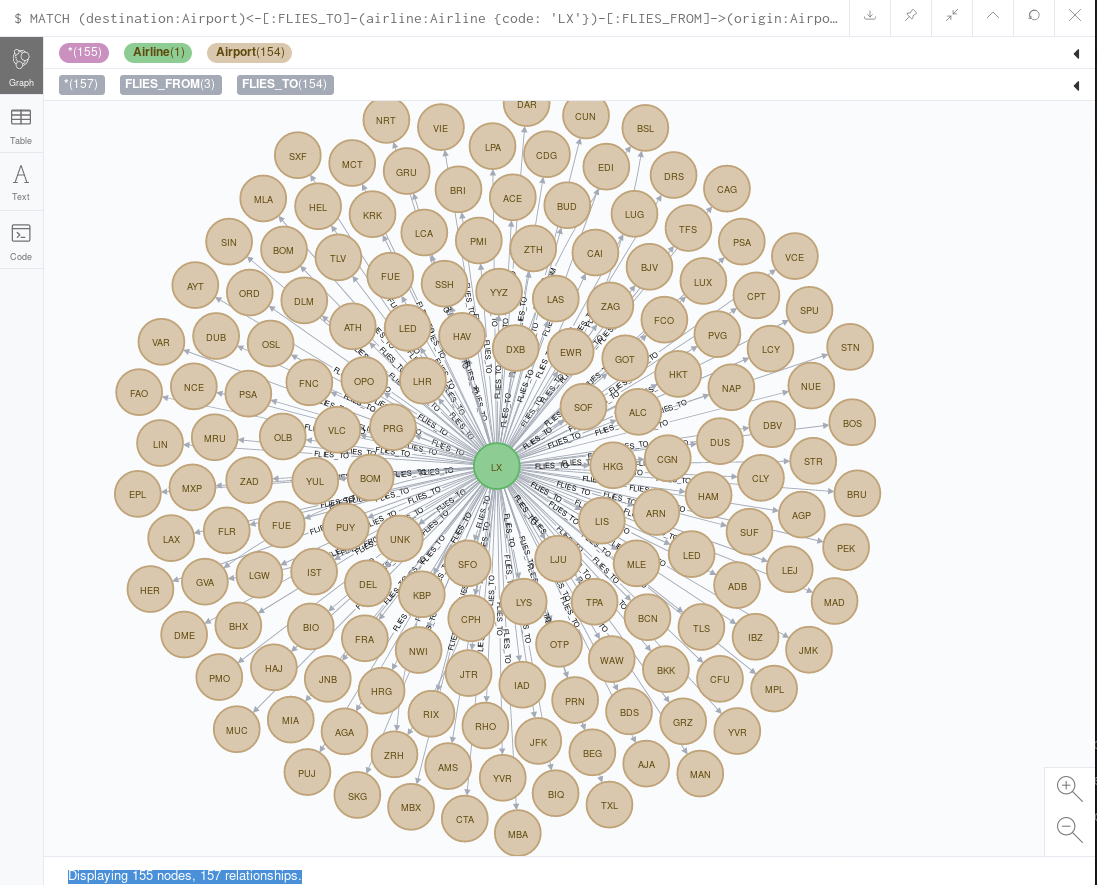
As you can see, configuring Neo4j to use Kafka as a streaming source is straightforward. The developers of the connector have made a good choice to use cypher as the connecting part between Kafka topics and Neo4j. This way, you have the greatest flexibility to handle the data from Kafka using the power of cypher.
Besides kafa and Neo4j, Apache Nifi is used for the dataflow management. It is a very good tool for dataflows: flexible, scalable, has many connectors and is the tool when it comes to schemas (inherit, infere), data provenance and then routing the data to various target systems.
Carpe Diem
Besides kafa and Neo4j, Apache Nifi is used for the dataflow management. It is a very good tool for dataflows: flexible, scalable, has many connectors and is the tool when it comes to schemas (inherit, infere), data provenance and then routing the data to various target systems.
Carpe Diem



 RSS Feed
RSS Feed
