
Recently I have spent some time on Apache Hadoop. I had a basic idea already of what it does, but I wanted to learn and understand more about how it works and then of course I wanted to try it out.
So I started reading documentation to understand the basic concepts. There is a lot of documentation out there and so I spent also considerable time finding the "right" documentation. "Right" in the sense of "recent" - there is a lot of info out there that is not one-to-one applicable for the recent versions.
I then downloaded Hadoop, installed it on my laptop and ran the famous wordcount mapreduce job. That is straight-ahead and worked quickly. And so I did further tests with more data and with larger CSV files.
As I am also a Java developer (besides other things), I created a project in Eclipse and started coding my first mapreduce job to get a feeling for how easy or not that is. The map and the reduce idea is easy enough but then there are a lot of details to watch out. But finally I had my own mapreduce job that reads from a CSV file and outputs the results of the defined key and the sum of a certain column in the file.
My next step was to modify the mapreduce code in a way, that I can dynamically select the columns from the CSV file that make up the key and the column that I want to use for summing. I did this by loading this information from a properties file external to the job. There is still a lot to learn, but at this point I had a working version of my own mapreduce job.
Hadoop is all about parallel processing, so the next step was to setup a cluster. I do not have multiple machines at hand, but I have a few Raspberry PI mini computers lying around, so I decided I give it a go. A portable Hadoop cluster seemed to be a nice idea.
Here is a picture of the final result:
So I started reading documentation to understand the basic concepts. There is a lot of documentation out there and so I spent also considerable time finding the "right" documentation. "Right" in the sense of "recent" - there is a lot of info out there that is not one-to-one applicable for the recent versions.
I then downloaded Hadoop, installed it on my laptop and ran the famous wordcount mapreduce job. That is straight-ahead and worked quickly. And so I did further tests with more data and with larger CSV files.
As I am also a Java developer (besides other things), I created a project in Eclipse and started coding my first mapreduce job to get a feeling for how easy or not that is. The map and the reduce idea is easy enough but then there are a lot of details to watch out. But finally I had my own mapreduce job that reads from a CSV file and outputs the results of the defined key and the sum of a certain column in the file.
My next step was to modify the mapreduce code in a way, that I can dynamically select the columns from the CSV file that make up the key and the column that I want to use for summing. I did this by loading this information from a properties file external to the job. There is still a lot to learn, but at this point I had a working version of my own mapreduce job.
Hadoop is all about parallel processing, so the next step was to setup a cluster. I do not have multiple machines at hand, but I have a few Raspberry PI mini computers lying around, so I decided I give it a go. A portable Hadoop cluster seemed to be a nice idea.
Here is a picture of the final result:

The top PI (PI 3) is my namenode the other three (PI 2) are my datanodes. So the top one is the master who organizes and coordinates things and the other ones are doing the mapreduce work.
Again, there is lots of information on the net but also a lot of outdated information. Initially I had three PI's where the first one was the master but at the same time being also a datanode. I spent many days to find a working configuration. I arrived at a point where the cluster was active and working, but only the master was doing the mapreduce work. After a lot of research I found out that the other nodes were not communicating with the ResourceManger daemon. I updated the configuration and finally had a cluster where all PI's are working together.
And then finally I wanted to see how easy it is to add one more datanode to the cluster. I added more more PI and changed the configuration for the first one to not being a datanode.
What you see above is now working. A cluster with 4 computers based on Hadoop 2.7.3. I uploaded two CSV files into HDFS. Both contain 50000 lines. So I have 100000 lines to be processed. The mapreduce calculates the sum of one field and output the results for a key that is made up of three fields.
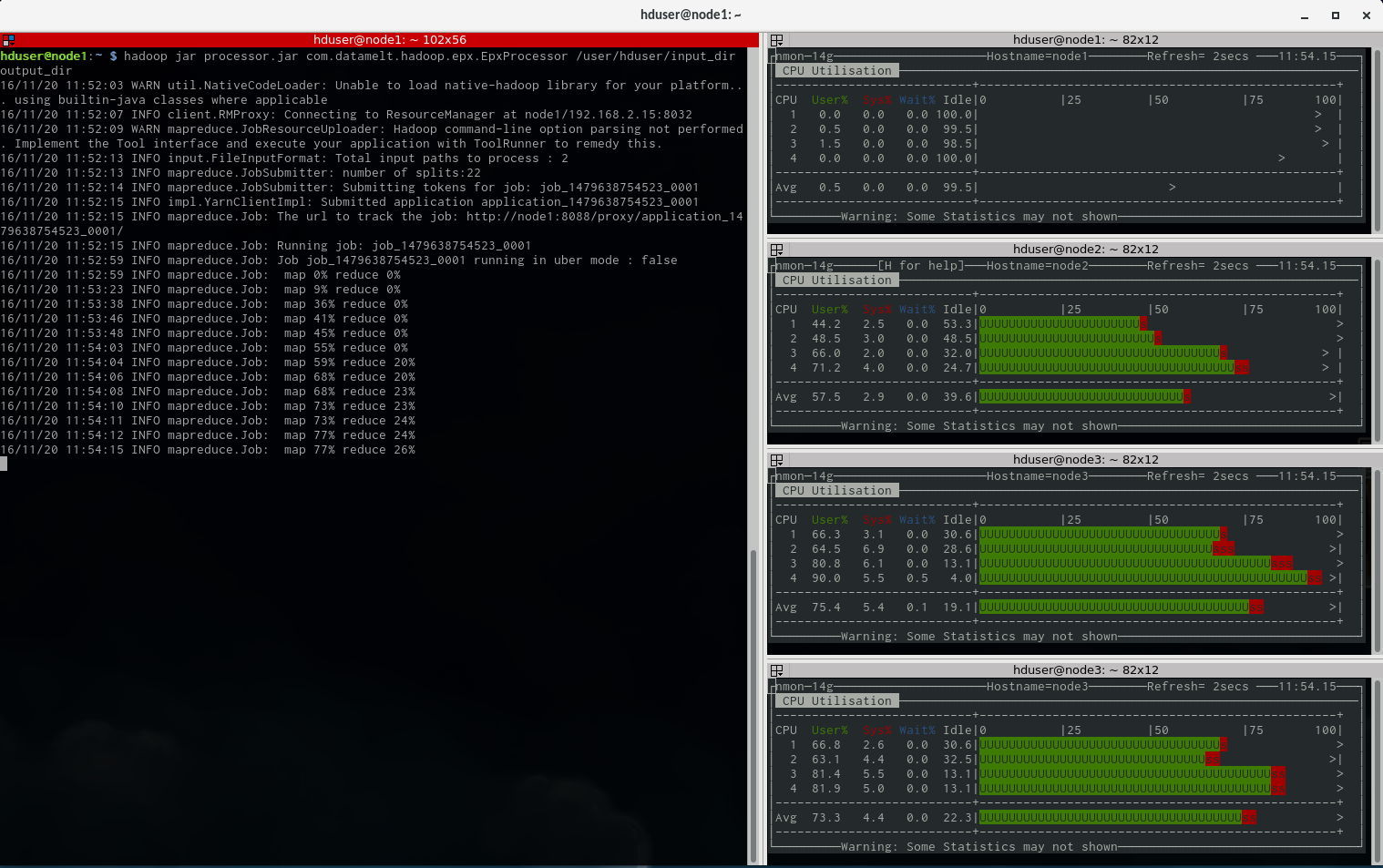
And below is a screenprint of the cluster working on the mapreduce job. On the right are 4 monitors (using nmon) for the nodes and on the left is the output from the madreduce job.
Again, there is lots of information on the net but also a lot of outdated information. Initially I had three PI's where the first one was the master but at the same time being also a datanode. I spent many days to find a working configuration. I arrived at a point where the cluster was active and working, but only the master was doing the mapreduce work. After a lot of research I found out that the other nodes were not communicating with the ResourceManger daemon. I updated the configuration and finally had a cluster where all PI's are working together.
And then finally I wanted to see how easy it is to add one more datanode to the cluster. I added more more PI and changed the configuration for the first one to not being a datanode.
What you see above is now working. A cluster with 4 computers based on Hadoop 2.7.3. I uploaded two CSV files into HDFS. Both contain 50000 lines. So I have 100000 lines to be processed. The mapreduce calculates the sum of one field and output the results for a key that is made up of three fields.
And below is a screenprint of the cluster working on the mapreduce job. On the right are 4 monitors (using nmon) for the nodes and on the left is the output from the madreduce job.
To get it all running and to gather all the information it took a while, but I have learnt a lot of things around Hadoop and the ecosystem as well. I will post more in the next time.
If anybody is interested in the configuration details, let me know - I am happy to share it.
Carpe Diem
If anybody is interested in the configuration details, let me know - I am happy to share it.
Carpe Diem
 RSS Feed
RSS Feed
