
Here is the second part of the blog post about Pentaho PDI and Apache Ignite - with more details. And here is the link to the first part of it.
So the first part discussed the general setup and the why it can be interesting to use Apache Ignite as an in-memory database for an ETL process: it acts as an in-memory storage layer for your data transformations.
Here is again the screenshot of the completed ETL
So the first part discussed the general setup and the why it can be interesting to use Apache Ignite as an in-memory database for an ETL process: it acts as an in-memory storage layer for your data transformations.
Here is again the screenshot of the completed ETL
I am using the geonames.org files as a data sources. Geonames has over 11 million geographical placenames and details available for free.
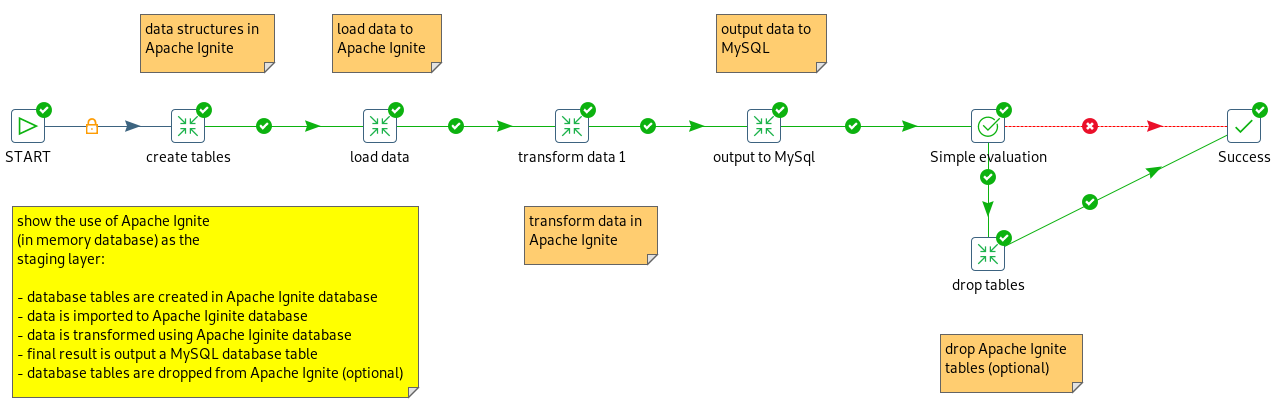
At the beginning the tables and structures in Apache Ignite are created using ExecuteSQL Script steps. This is what the complete transformation looks like:
At the beginning the tables and structures in Apache Ignite are created using ExecuteSQL Script steps. This is what the complete transformation looks like:

create tables
Five tables are created in Ignite. The last step at the bottom is to create the output table in MySQL, to persists the results of the transformation job there.
Here is an example - just a normal create table statement.
Here is an example - just a normal create table statement.
Execute Script code
To execute the script(s) you need a connection to the Ignite server: Select "Generic Database" as type and insert the URL and the JDBC driver class name and test the connection.
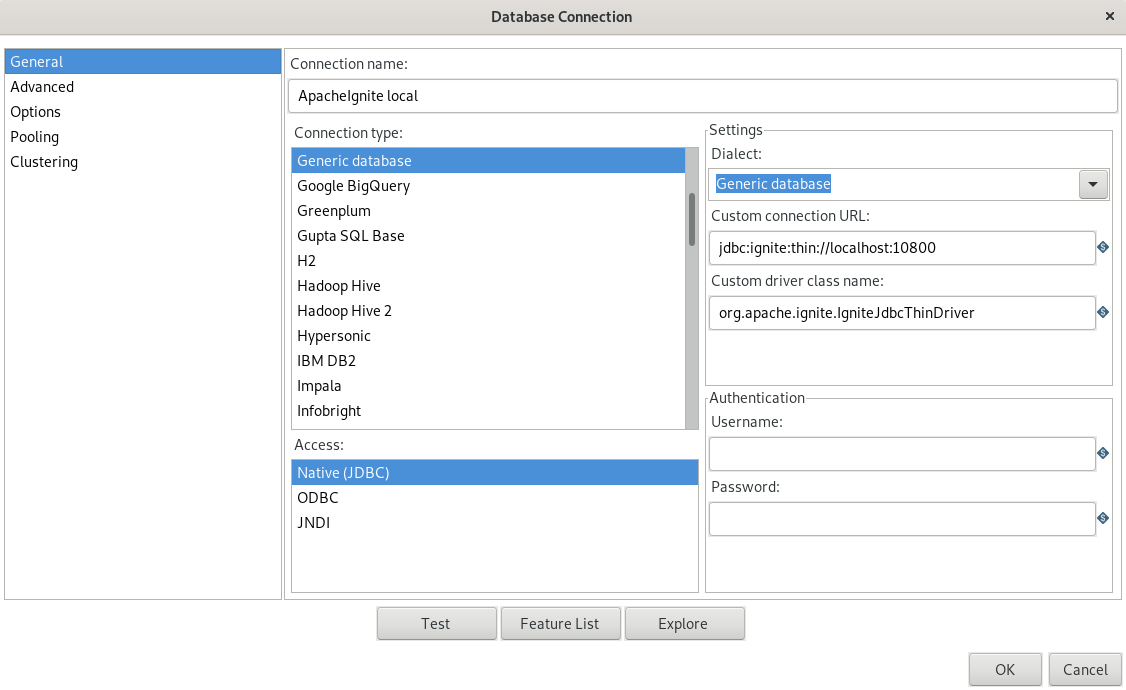
define database connection
In the next transformation the source data (from files) is loaded into the Apache Ignite database tables.
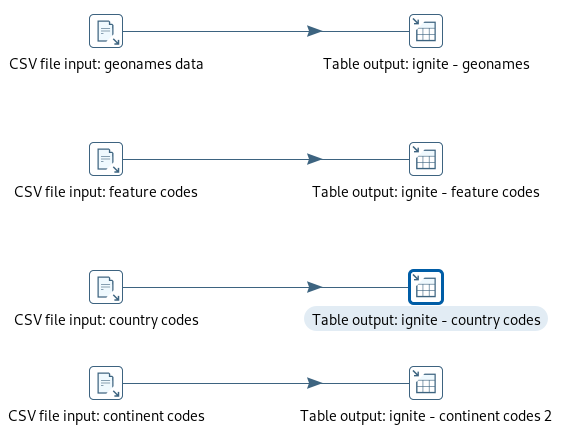
load data
The next step handles the transformation of the data. All processing is done in Ignite in memory. The data is read from Ignite and then some lookups from other tables are done to join data with information on country and continent as well as on feature codes. Finally it is output to another table in Ignite.
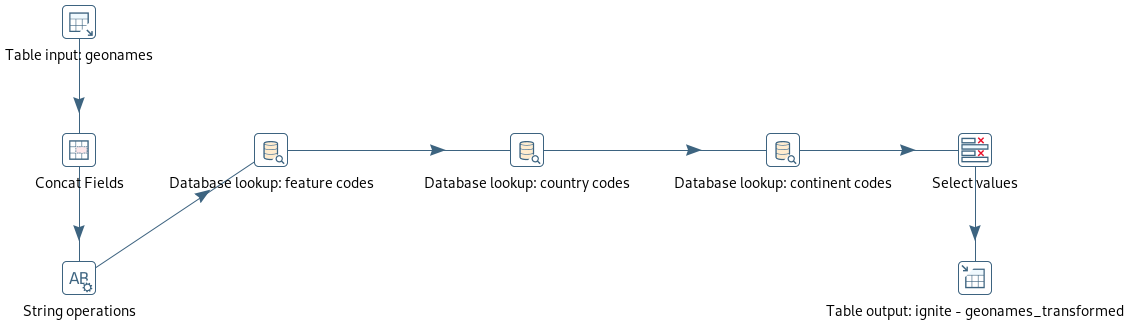
transform data
And finally the data is output from the table in Ignite which contains the transformed data to a MySQL table.

The last step can be to drop all tables from Ignite, if they are not required. This is done by passing a parameter (true/false) to the transformation job. In some cases one will want to keep the data to review the transformation steps and results but then in other cases, it might not be required anymore so we can delete it and free the memory occupied in Ignite.
This might not be so interesting, but I wanted to find out if a whole processing chain works without issues and that PDI and Ignite work well together. And they do! It is rather easy to replace an existing connection to a traditional database, with one to Apache Ignite. As it supports JDBC and SQL there won't be a big effort to redesign the transformation job. All steps I have tested work out of the box with Ignite: creating DDL statements, querying, deleting, etc.
Issues:
There is a minor issue though, which I found: when PDI reads the data from Ignite, then all columns of type "String" have a length of "30". All - independent if they are defined shorter or longer in the database schema. Here is the create table statement of one of the tables:
This might not be so interesting, but I wanted to find out if a whole processing chain works without issues and that PDI and Ignite work well together. And they do! It is rather easy to replace an existing connection to a traditional database, with one to Apache Ignite. As it supports JDBC and SQL there won't be a big effort to redesign the transformation job. All steps I have tested work out of the box with Ignite: creating DDL statements, querying, deleting, etc.
Issues:
There is a minor issue though, which I found: when PDI reads the data from Ignite, then all columns of type "String" have a length of "30". All - independent if they are defined shorter or longer in the database schema. Here is the create table statement of one of the tables:
Create table statement
And this is the table definition in Ignite:

Ignite table definition
But Pentaho PDI extracts it like this:

You can see all String type fields/columns are defined with a length "30". But no data is lost: it is just the definition of the column size that is wrong; data from Ignite that is longer than these 30 characters is correctly retrieved.
I have cross-checked this with a different SQL tool (Squirrel): I created a connection to Ignite using the same JDBC driver and retrieved the table definition details. This is what Squirrel shows:
I have cross-checked this with a different SQL tool (Squirrel): I created a connection to Ignite using the same JDBC driver and retrieved the table definition details. This is what Squirrel shows:

As Squirrel shows the correct length, I do not think it is a problem with the JDBC driver. It seems to be an issue in Pentaho PDI. So I have opened a Jira ticket for this and hope somebody will have a look at it.
As the size/length of the columns is wrong, one will have to manually change these in a "Select Values" step, so that e.g. when the data is output to a table, PDI generates the correct DDL statement, with the correct lengths.
Hope this helps to get an overview or get started. It's worth a try especially if you have a good use case for processing data in memory.
Carpe Diem
As the size/length of the columns is wrong, one will have to manually change these in a "Select Values" step, so that e.g. when the data is output to a table, PDI generates the correct DDL statement, with the correct lengths.
Hope this helps to get an overview or get started. It's worth a try especially if you have a good use case for processing data in memory.
Carpe Diem
 RSS Feed
RSS Feed
