
The JaRE ruleengine is a tool to generically run business rules against a given set of data. A typical use case would be to read data from a source file, run it thought the ruleengine and then filter the output based on the results of the ruleengine.
But we really do not want to create one ETL per source file. We would duplicate a lot of the process just because of the different layout of the input file. If you have many input files, then that is difficult to a) create and b) to do maintenance over time. And this ultimately is a quality issue.
But there is a better way to do it - at least in Pentaho PDI (Kettle) - the Pentaho ETL tool! Metadata Injection comes to our help. Using metadata injection one can pipe the definitions/settings for an Step in PDI into a transformation. So e.g. the field names, their data types, lengh, etc. Or the delimiter used, the file encoding or if a header row is present. So instead of hardcoding the layout into a Step, it is loaded dynamically from e.g. a file.
The advantage is, that you can create one single ETL that will run for many different input files. And one ETL is easier to maintain than many.
For this example I use following use case:
Note: Instead of using files you could use a database or any other source as long as the step/plugin supports metadata injection.
Here is a screenprint of the process.
But we really do not want to create one ETL per source file. We would duplicate a lot of the process just because of the different layout of the input file. If you have many input files, then that is difficult to a) create and b) to do maintenance over time. And this ultimately is a quality issue.
But there is a better way to do it - at least in Pentaho PDI (Kettle) - the Pentaho ETL tool! Metadata Injection comes to our help. Using metadata injection one can pipe the definitions/settings for an Step in PDI into a transformation. So e.g. the field names, their data types, lengh, etc. Or the delimiter used, the file encoding or if a header row is present. So instead of hardcoding the layout into a Step, it is loaded dynamically from e.g. a file.
The advantage is, that you can create one single ETL that will run for many different input files. And one ETL is easier to maintain than many.
For this example I use following use case:
- read a CSV file - row by row
- run the data through the ruleengine to check the data
- ouput the rows that pass the checks of the ruleengine to a CSV file
- dump the rows that fail the checks of the ruleengine
- output a file with the detailed results of the ruleengine
Note: Instead of using files you could use a database or any other source as long as the step/plugin supports metadata injection.
Here is a screenprint of the process.
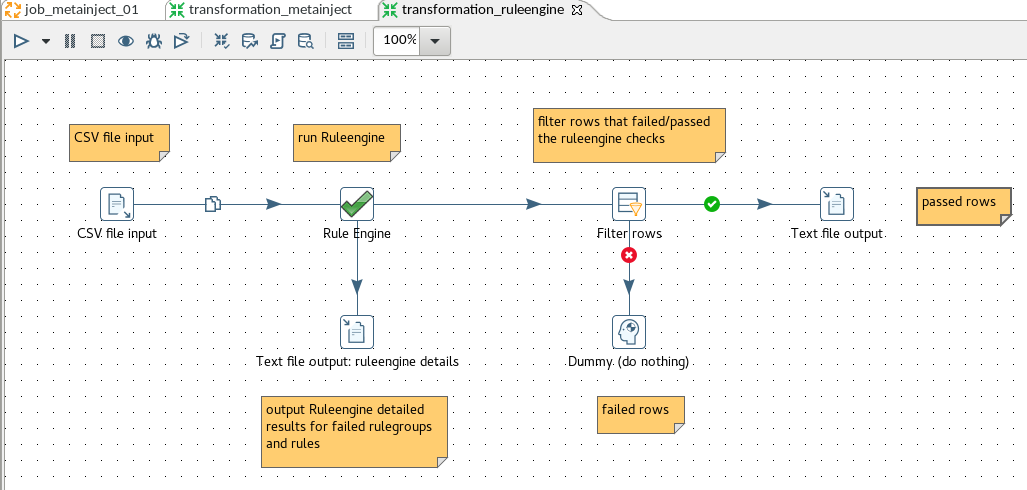
The "CSV file input" step, the "Text file output" step and the "Text file output: ruleengine details" step contain no details about fields, data types or other settings.
And there is another transformations that collects the data that will be injected into this transformation. Look here:
And there is another transformations that collects the data that will be injected into this transformation. Look here:
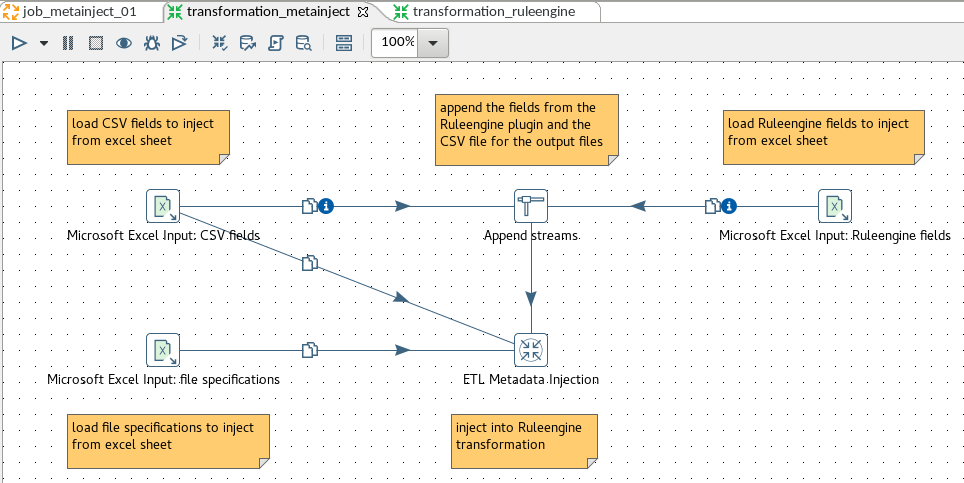
There are three Excel sheets involved:
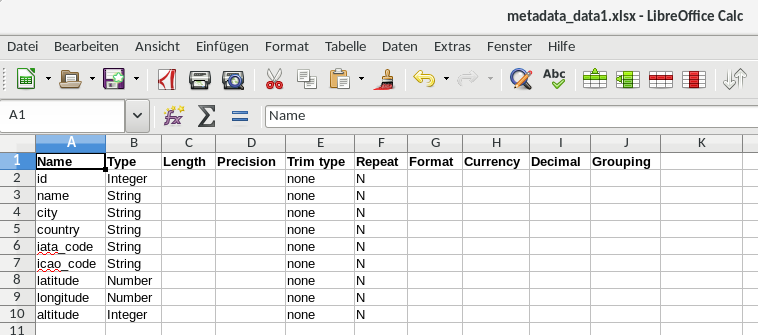
The first Excel sheet looks like shown below - a definition (metadata) of the input file fields of the file that contains the data. In this case it has 9 fields.
- a sheet with the definitions of the fields, data types and other details of the input field
- a sheet with the file input and file output specifications (encoding, header row, delimiter, etc)
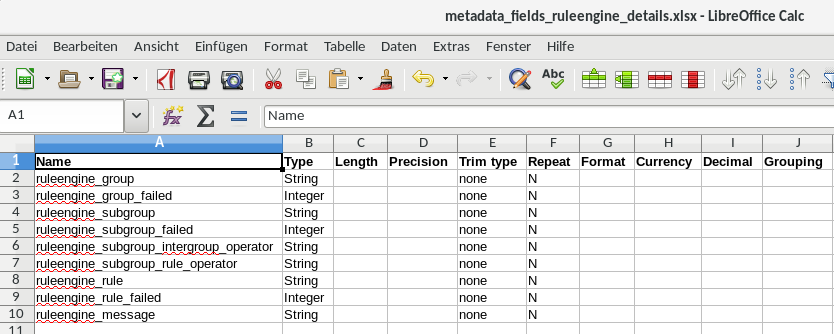
- a sheet with the fields that the ruleengine always adds to each row of processed data
The first Excel sheet looks like shown below - a definition (metadata) of the input file fields of the file that contains the data. In this case it has 9 fields.
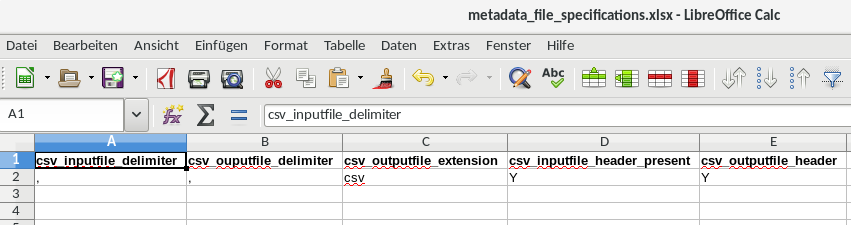
The second Excel sheet looks like one the screenprint below: extra information to steer how the input and output files are formatted:
The last sheet is shown below. It lists the fields that the ruleengine adds to each row. These fields indicate if the group and rule failed and the relevant message.
Now if you have 10 CSV files with data and they are all formatted differently, with different content, then this one ETL will be able to process them all! All you have to do is to create an Excel sheet (like the first one) which defines the fields, data types, etc. of the input file (for each input file).
So Metadata Injection is a generic way of processing different source data files in an elegant way. The name and location of the inputfile and the sheet that contains the layout can be passed as parameters to the ETL.
The next good point is, that the business rules are maintained and orchestrated outside the ETL process - no need to hardcode them. A free web application is available to do this. So the ETL accepts another parameter that defines the name and location of the file that contains the business rules details.
And voila, you have a generic ETL to handle arbitary CSV files, process them with the rule engine and output the results. As mentioned before, the ouput can be all the rows that passed the checks of the ruleengine - so that is a sort of filter applied based on the ruleengine results. And the other file that is output contains the detailed results of each row for each rule.
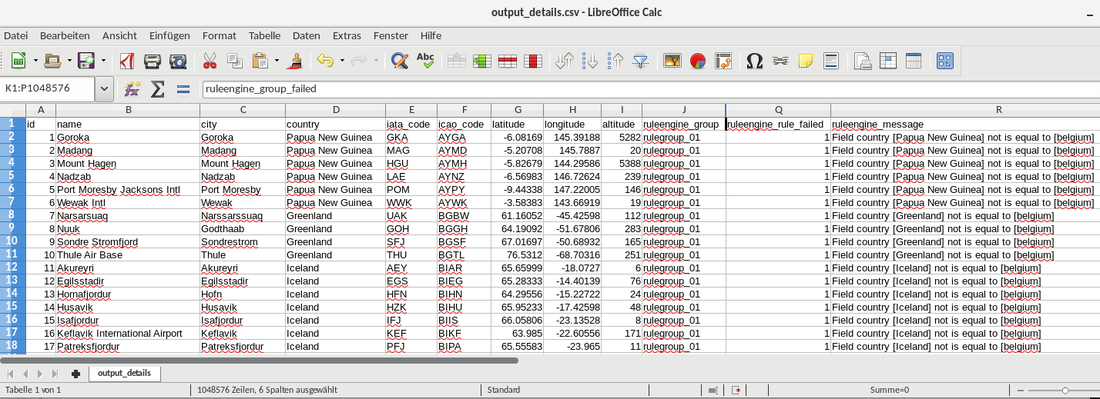
Here is the screenshot (I have hidden some of the not so important columns, otherwise the screenshot would have been too wide to read it properly). In this case I had simply one rule to check if the country equals to "belgium". These results give you a very good means to find out which data did not fit to (pass) the business rules.
So Metadata Injection is a generic way of processing different source data files in an elegant way. The name and location of the inputfile and the sheet that contains the layout can be passed as parameters to the ETL.
The next good point is, that the business rules are maintained and orchestrated outside the ETL process - no need to hardcode them. A free web application is available to do this. So the ETL accepts another parameter that defines the name and location of the file that contains the business rules details.
And voila, you have a generic ETL to handle arbitary CSV files, process them with the rule engine and output the results. As mentioned before, the ouput can be all the rows that passed the checks of the ruleengine - so that is a sort of filter applied based on the ruleengine results. And the other file that is output contains the detailed results of each row for each rule.
Here is the screenshot (I have hidden some of the not so important columns, otherwise the screenshot would have been too wide to read it properly). In this case I had simply one rule to check if the country equals to "belgium". These results give you a very good means to find out which data did not fit to (pass) the business rules.
Metadata Injection is an elegant way to handle such use cases. And it is easily done in Pentaho PDI. It helps when your automizing processes and when you deal with many different formats.
Carpe Diem.
Carpe Diem.
 RSS Feed
RSS Feed
