
Here is a simple example of how to query a CSV file. We will go through the complete process of defining the storage, placing the CSV file in the filesystem and querying the file.
The assumption is, that you have a drillbit running on your localhost or some other machine that you can access. Open your web browser and go to http://localhost:8047.
You should see the start page of your drill instance like in the screenshot below.
Here is an excerpt from the file which is named "airports.csv". It is a list of airports and contains around 46000 records.. The individual fields are delimited by comma. The first row is a header row defining the names of the fields.
id,ident, airport_type, name, latitude, longitude, elevation, continent, country, region, municipality
6523,00A,heliport,Total Rf Heliport,40.0708007813,-74.9336013794,11,NA,US,US-PA,Bensalem
6524,00AK,small_airport,Lowell Field,59.94919968,-151.695999146,450,NA,US,US-AK,Anchor Point
6525,00AL,small_airport,Epps Airpark,34.8647994995,-86.7703018188,820,NA,US,US-AL,Harvest
6526,00AR,heliport,Newport Hospital & Clinic Heliport,35.6086997986,-91.2548980713,237,NA,US,US-AR,Newport
6527,00AZ,small_airport,Cordes Airport,34.3055992126,-112.1650009155,3810,NA,US,US-AZ,Cordes
6528,00CA,small_airport,Goldstone /Gts/ Airport,35.3504981995,-116.888000488,3038,NA,US,US-CA,Barstow
6529,00CO,small_airport,Cass Field,40.6222000122,-104.34400177,4830,NA,US,US-CO,Briggsdale
6531,00FA,small_airport,Grass Patch Airport,28.6455001831,-82.21900177,53,NA,US,US-FL,Bushnell
6532,00FD,heliport,Ringhaver Heliport,28.8465995789,-82.3453979492,25,NA,US,US-FL,Riverview
The first thing we will do now is to define the location in the filesystem, where drill will look for the CSV file. On the drill web page click on "Storage". You get a list of enabled and disabled storage plugins. Make sure that "dfs" (distributed file system) is enabled. If it's not then click on the "Enable" button next to it. Now click on "Update" because we will modify the configuration defining the location of the CSV file and the CSV file format.. A page with a label "Configuration" at the top is displayed. As shown on the screensprint below, I entered a value of "local" respresenting the name of the schema - under "workspaces". "location" defines the place in the filesystem, where drill looks for the file - in this case the location is set to "/data".
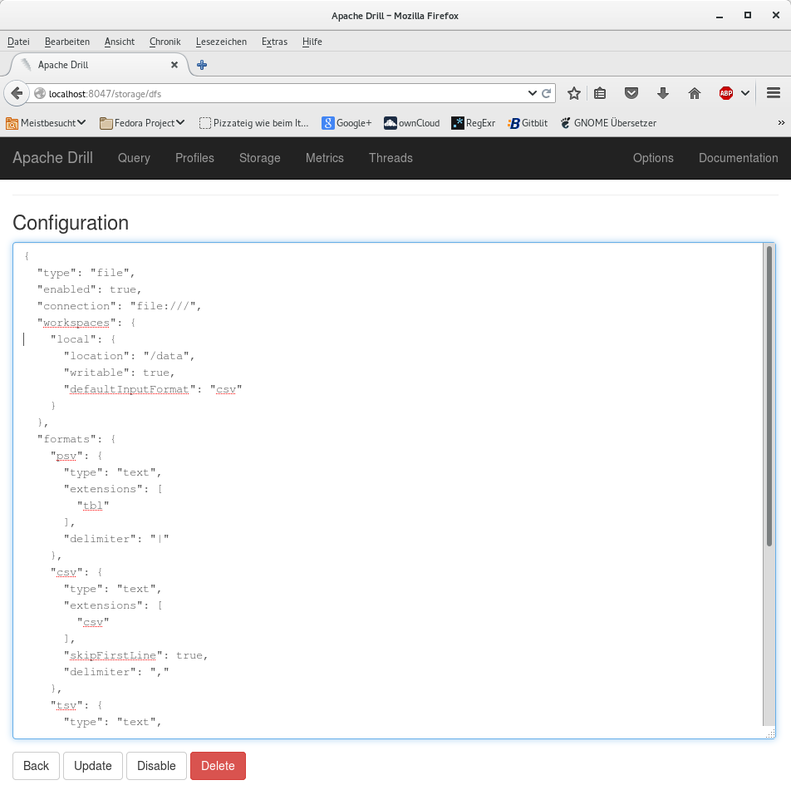
Further down - under "formats" - there is the definition for the CSV format. Note that "extension" is set to "csv" - the file extension. Then there is an entry for "skipFirstLine". It is set to "true" because we have a header line in the CSV file, which we want to skip - otherwise drill treats it as a regular line of data. And then there is an entry for "delimiter" which defines how the individual fields are seperated - in this case by a comma.
Once you have entered the details, click on "update" to store your changes. The configuration page will show a message "success" at the bottom if everything entered was in the correct format.
Now copy or place the CSV file "airports.csv" to the file system to the place that we defined in the drill storage configuration, which is "/data".
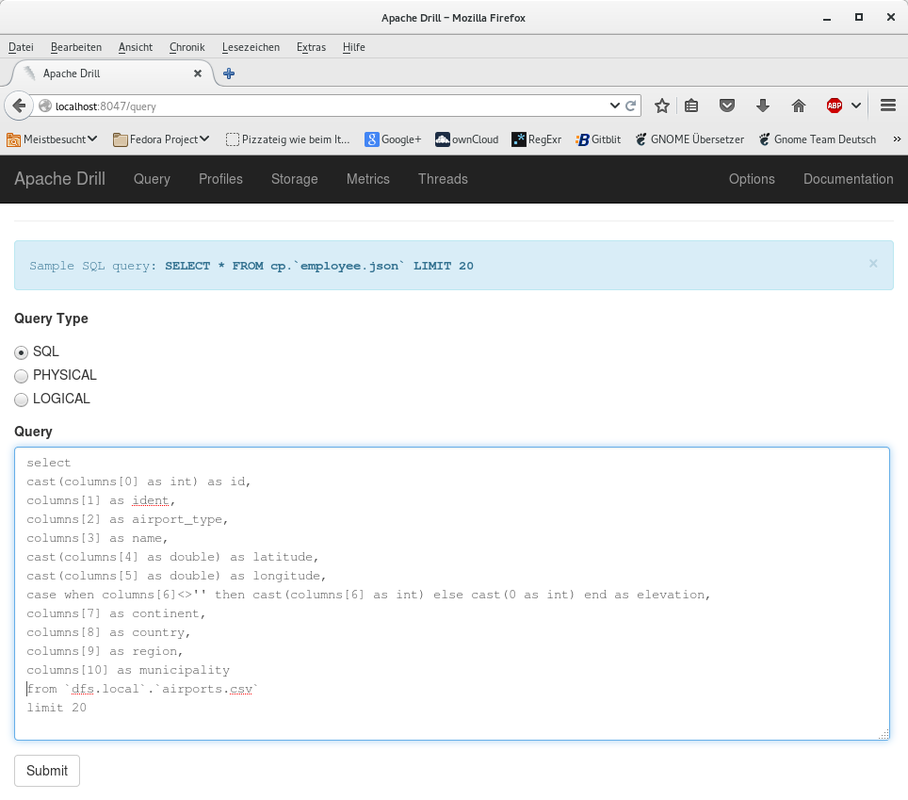
That's it. Drill is configured and the file is in place to be queried. On the drill web page click on "Query". Let's start with something easy and count the number of rows the file has. Enter the query as shown below. Note that "dfs" is the storage we have configured and "local" which we have defined in the configuration under "workspaces". These are enclosed in backticks. And then - again in backticks - there is the name of the csv file. Now all you have to do is to click on "Submit" to run the query.
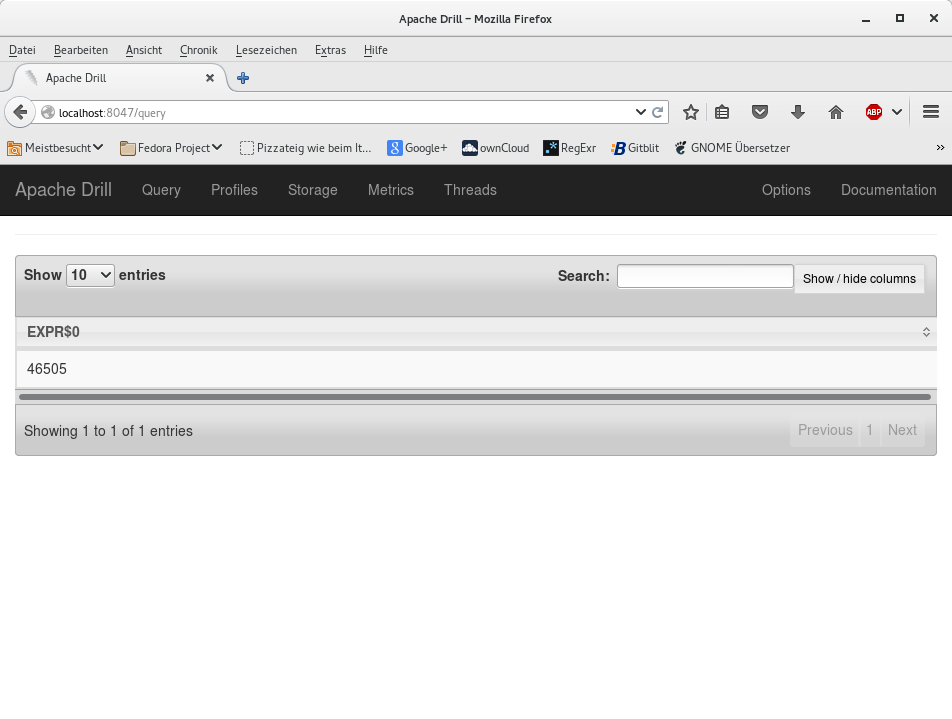
The query runs and quickly returns the result shown on the screenprint below. We have 46505 rows of data in the file. One line was skipped - the header row, because we defined it like this in the configuration.
Let's retrieve some records now the easy way by running another query. We select "*" to indicate that we want all fields of each row. And we specify a limit of 20, so that only 20 rows are returned - we do not want all 46505 rows being returned. Click on "Submit" to run the query.
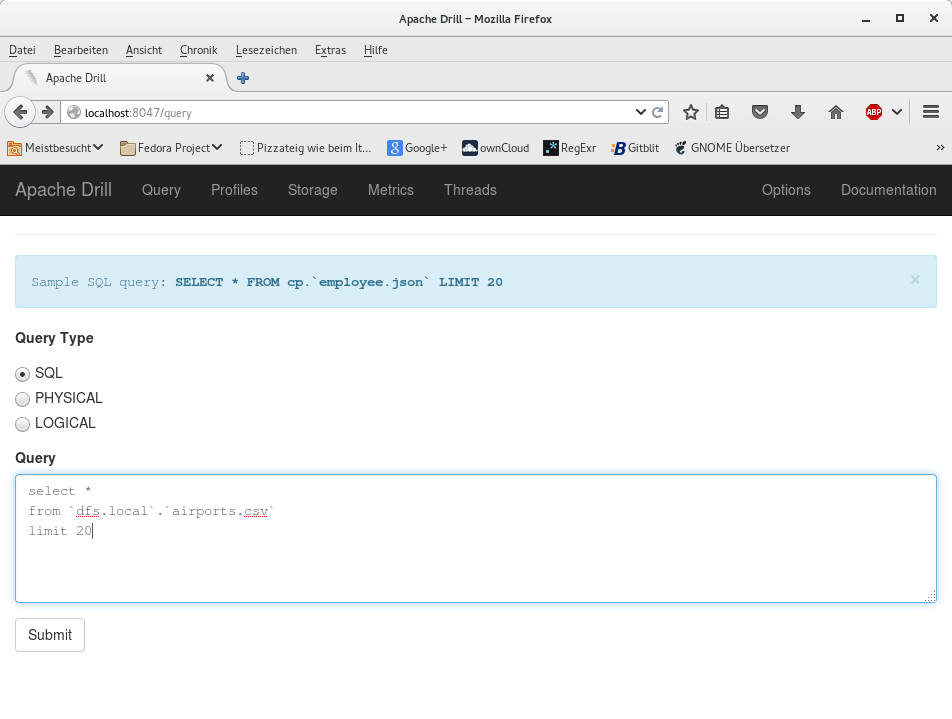
The query will return 20 rows. Drill pages the rows into chunks of 10 records. In the lower right you can go to the next page. In the upper right you can search for text in the result of the query. In the upper left you may define how many records per page are displayed.
Note that because we used "*", drill will return each record as an array of values.
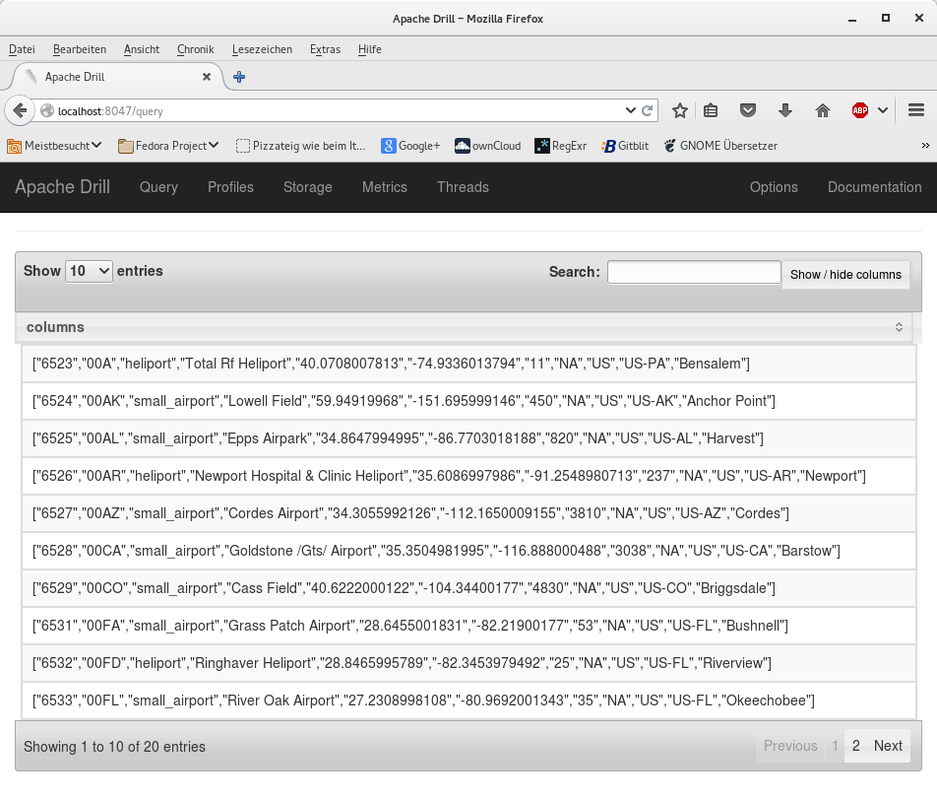
Now let's do a more sophisticated query. We will name the individual columns correctly and we will cast the columns to the correct type where appropriate. The first column "id" is a number so we cast it to an integer. Columns 4 and 5 are latitude and longitude position of the airport - we cast those to double. Column 6 (elevation) is tricky, because it contains an empty string for some of the records in the CSV file but for the other records it contains a number. I have used a case statement to differentiate between these and to always have an integer as the result using the cast function. Finally I limit the query to again return only 20 rows.
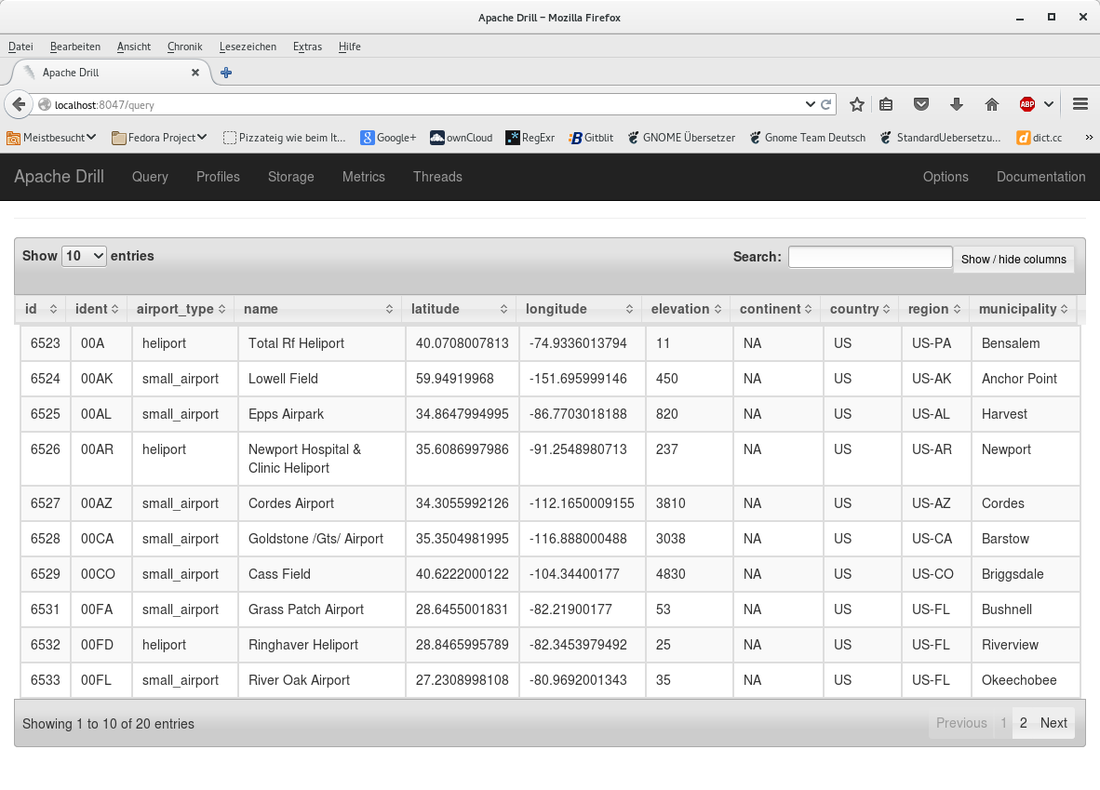
Here is the result from the query above. It nicely shows the fields with the correct types and allows us to do further queries on the data.
 RSS Feed
RSS Feed
