
For a while now I try to promote the idea of seperating the responsibilities in application maintenance. Many applications contain a mix of IT logic and Business logic. So the technical logic such as e.g. unzipping files, checking servers or folders, loading configuration files, accessing databases and much more is mixed with logic from the business: adjusting field values, manipulating data, calculating values.
So what is the problem? When you mix your regular IT code or processes with Business logic, then you - the IT expert - will always be the responsible to change it. Your responsilbe for changing both, because both is in IT related code or processes and the business does not understand much of that.
It is completely intransparent to the business user where the business logic is located in the middle of all the IT related stuff. Mixing of the logic is also a quality issue: The IT expert is not necessarily a business expert so changes to the IT system can go wrong when it breaks business logic that is in the middle of the development work.
Already in a moderately complex system, when you change IT related logic - e.g. application logic or an ETL process - then this might break the business logic. The other way around - if the business comes up with new or changed business logic - the business expert has no idea where that logic should end up in the IT process. So it is the IT expert to implement it. And it does not help a lot having the business user sitting next to you and watch your ETL flows, your database tools or your IDE. Changes to one or the other part of the system may break the other part. And IT will have to fix it in any case.
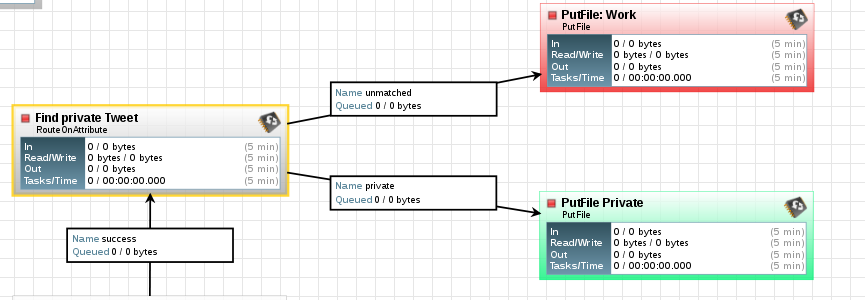
So this is what the screenprint below demonstrates. Changes to the system always require IT work, because the business delegates the work to IT - they can not do it!
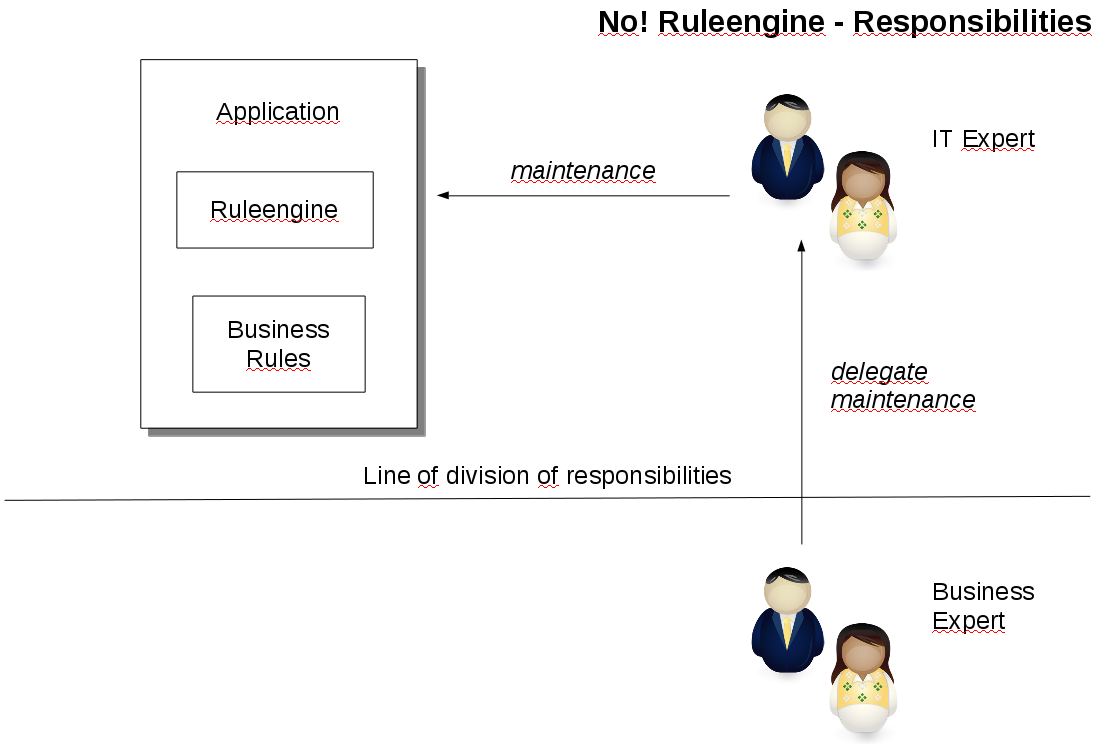
So why do we create this mixture of IT and business logic? Well sometimes the simple answer is, that in IT we have the best analytical thinking and the required tools. Another reason is that many times we are sitting in the middle: between a source system that can not be changed and a target system that takes a long time to change or is expensive to change (meaning it also can not be changed). ETL processes are a good example for this: IT has the tools and they are flexible, scalable and configurable. If source and target can not be changed, IT in the middle can do so. Many times IT is correcting, enhancing or streamlining data, because bad data comes from source systems and as indicated those are hard to change or the business processes capturing the data can not be changed.
IT code mixed with business logic is repeatedly not able to handle time constraints of the rules. Rules - e.g. for customers or contracts - sometimes have a validity date. I time when they are valid. Usually IT has to take care of that by changing the code at the right time to get the correct result at the correct time.
But mixing IT and business logic is not a good idea. It does not draw a concrete line between the responsibilities. The responsibilities should really be divided: IT is responsible for the IT logic and the technical implementation, support, architecture and the business defines the business logic. Both experts are responsible for that part that they know best.
When there is a clear division, then both parts can be adjusted seperately: IT changes the code or process, does the testing and migrates everything and it does not affect the business logic. Business logic changes are implemented seperately, are not mixed up with IT code and don't influence the IT part of the process.
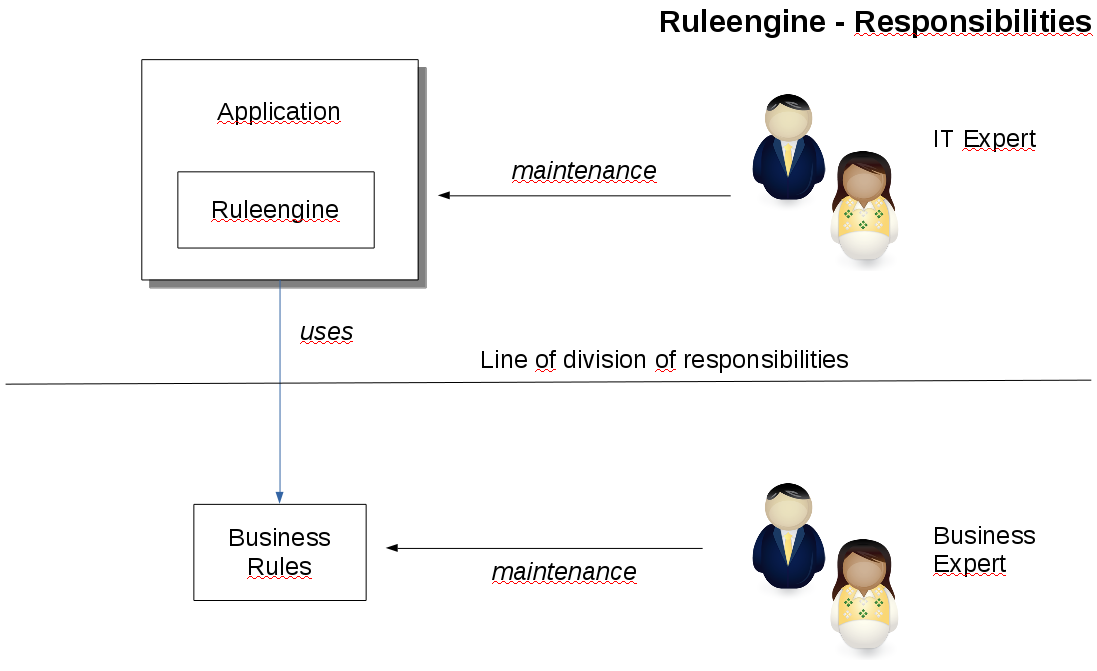
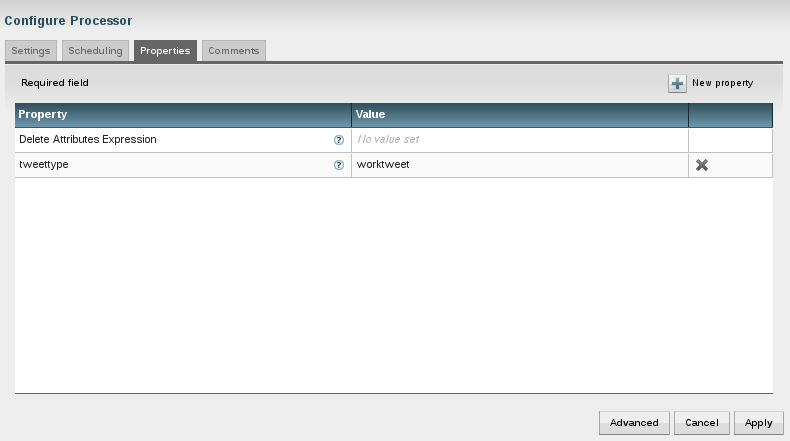
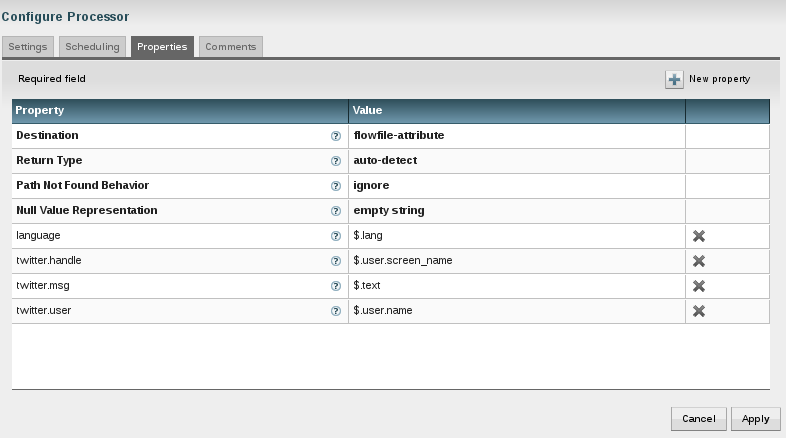
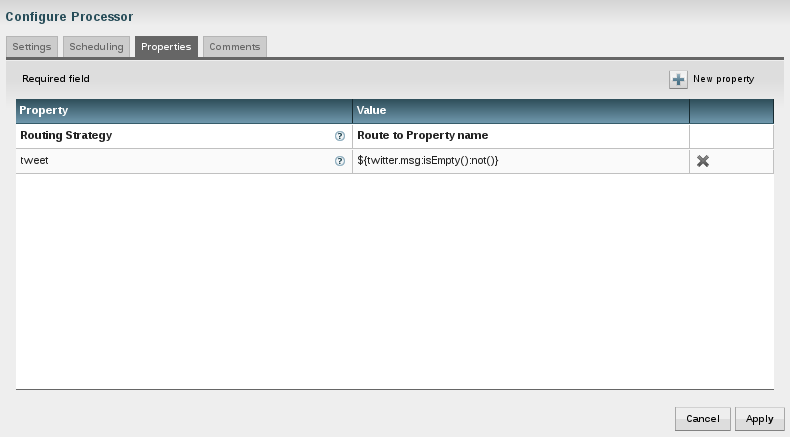
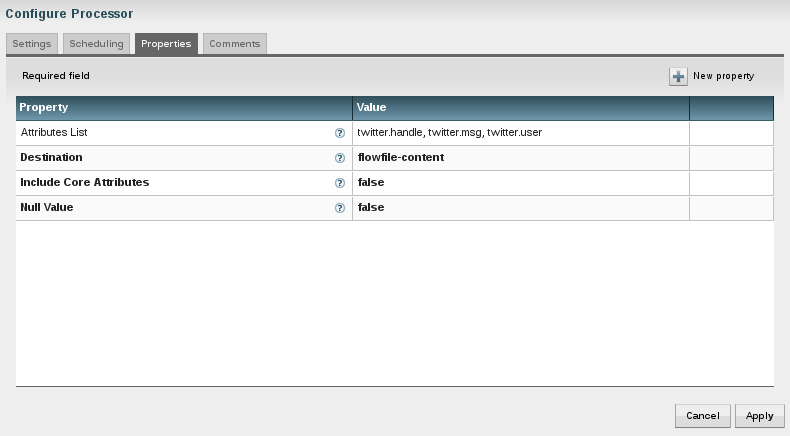
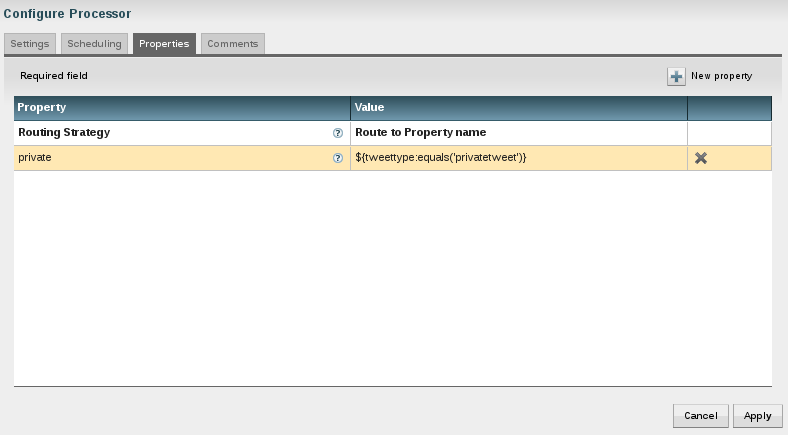
So how can this be achieved? Use a ruleengine! The idea is that there is an application that runs (or uses) a ruleengine. The ruleengine executes business rules. And the rules are defined in a seperate tool - external to the application. The application does for what it was built and only uses a set of rules and these are defined by the business. We have a clear distinction of responsibilities as shown below.
 RSS Feed
RSS Feed
