Just a quick note here: I have put the sample data that use in my blogs on github at:
0 Comments
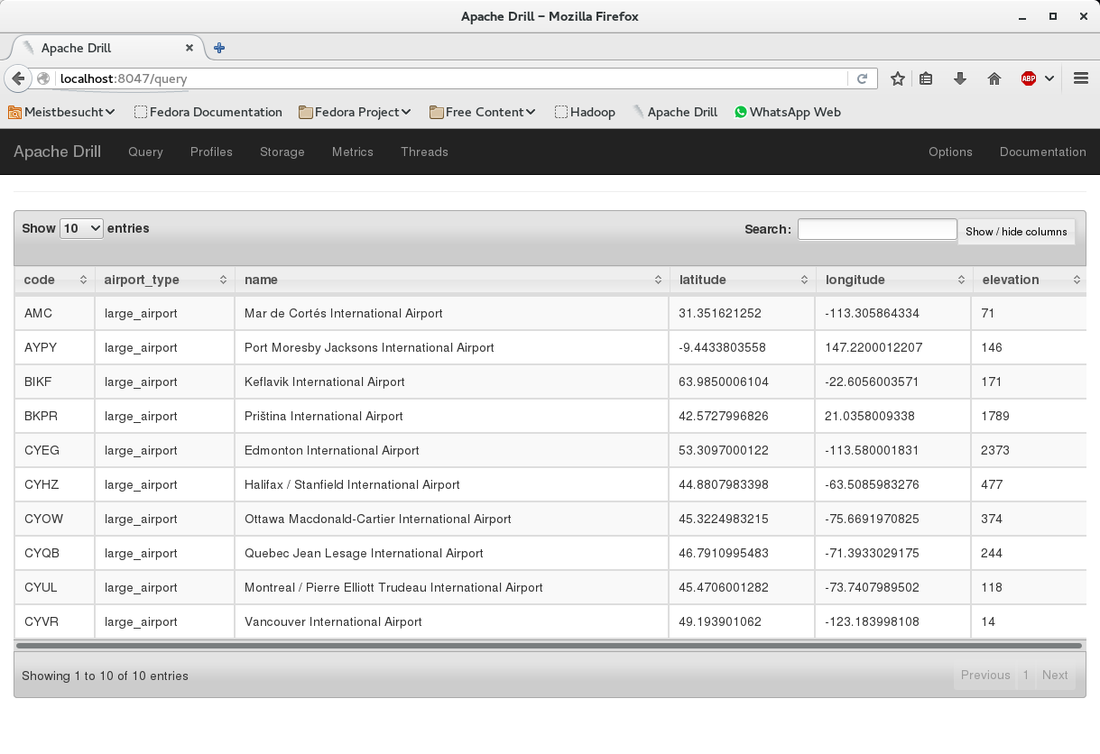
This is the last part of three parts. The last time we have queried a CSV file in Hadoop HDFS from Drill. 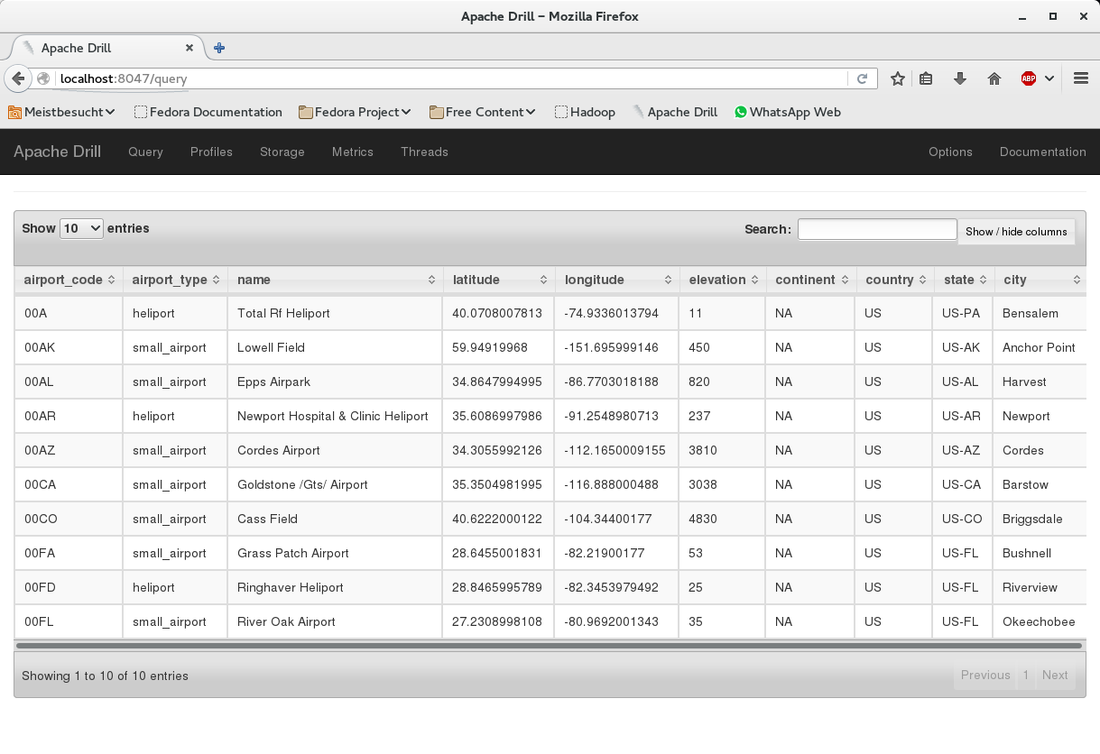 Now we will slightly change the query to create parquet files. Simply add the first line as shown below:  Go to the console window and check what has happened in the Hadoop filesystem: 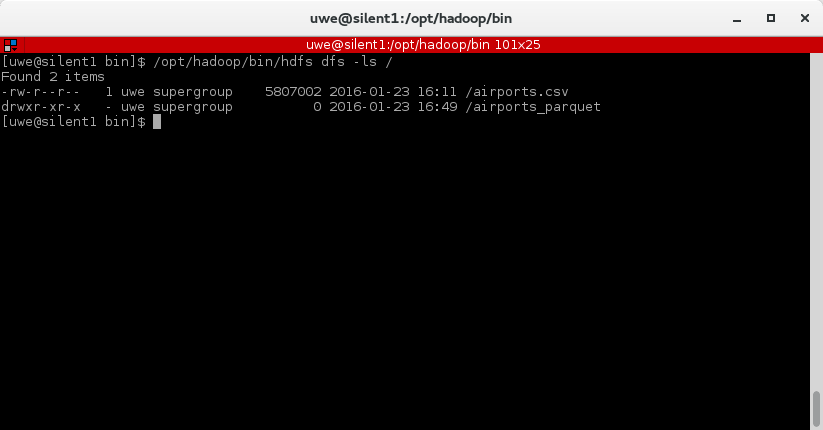 The folder "airports_parquet" was created as we used it as the table name in the "create table as" statement. Inside the folder there are the parquet files - one per continent: 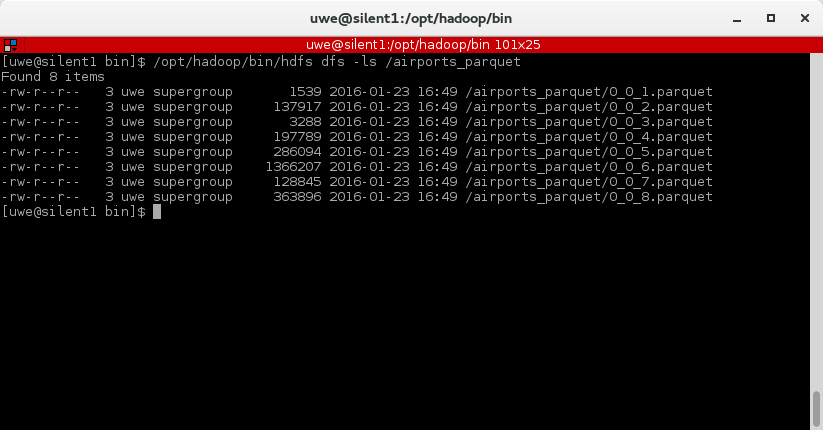 Now that we have the parquet files created, we can use them to query the airport data. Here is an example: 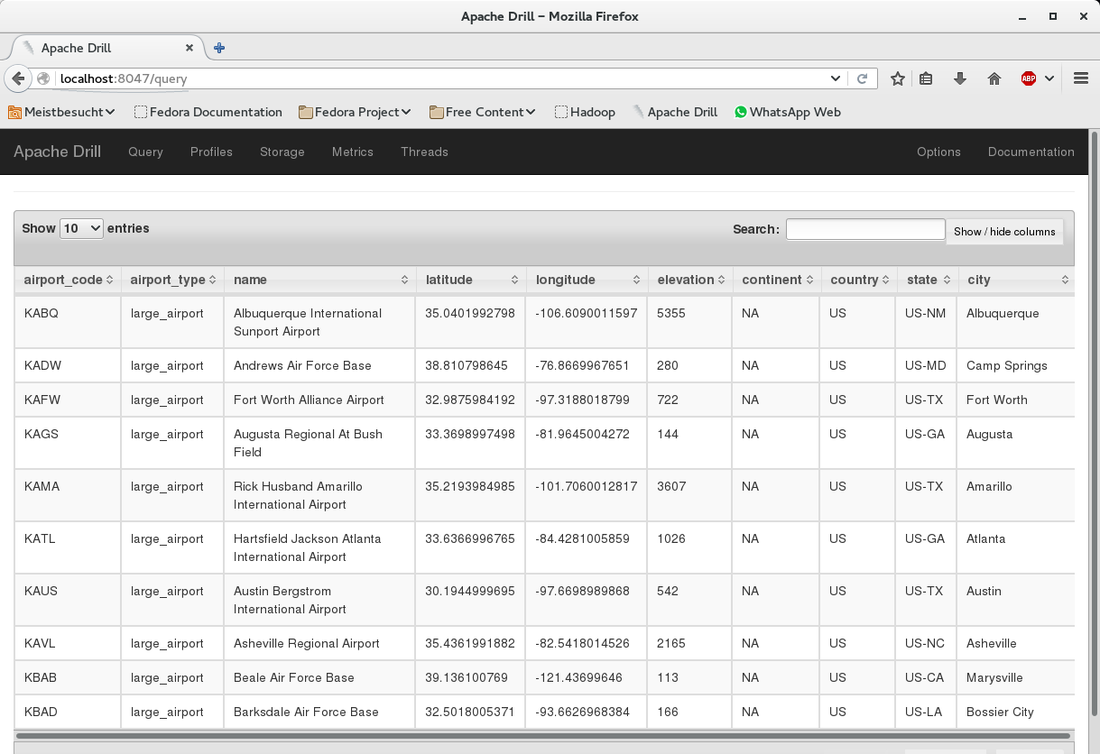 This is it. We have created parquet files from the CSV file. Parquet offers a better performance than CSV files and can easily be created from Drill.
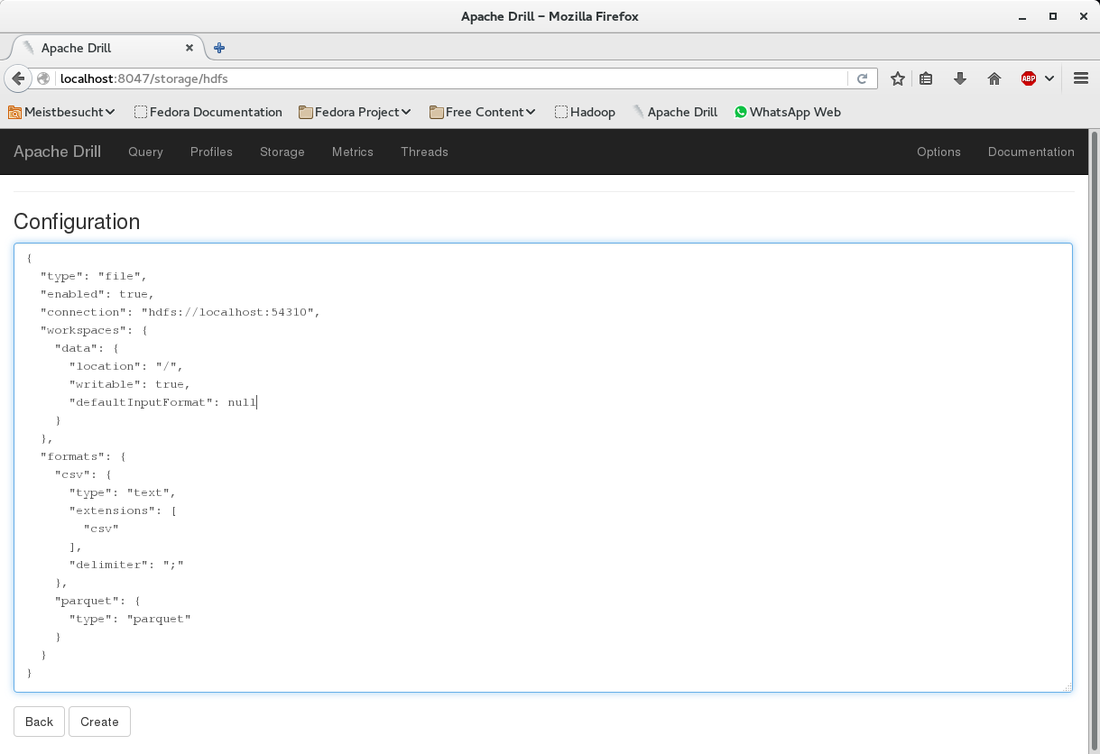
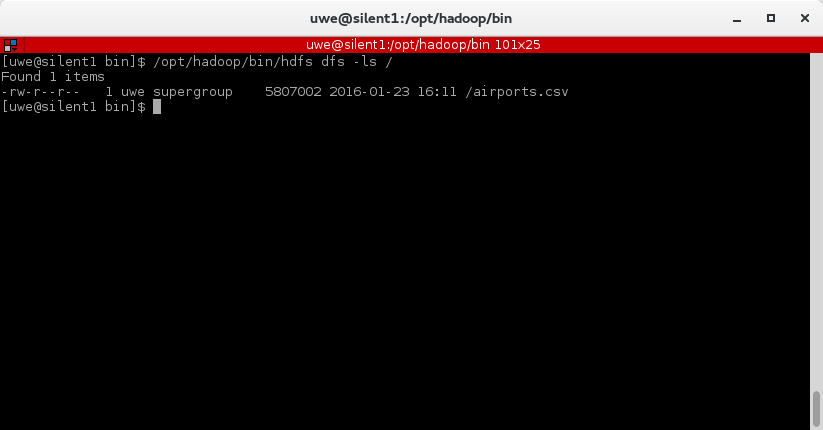
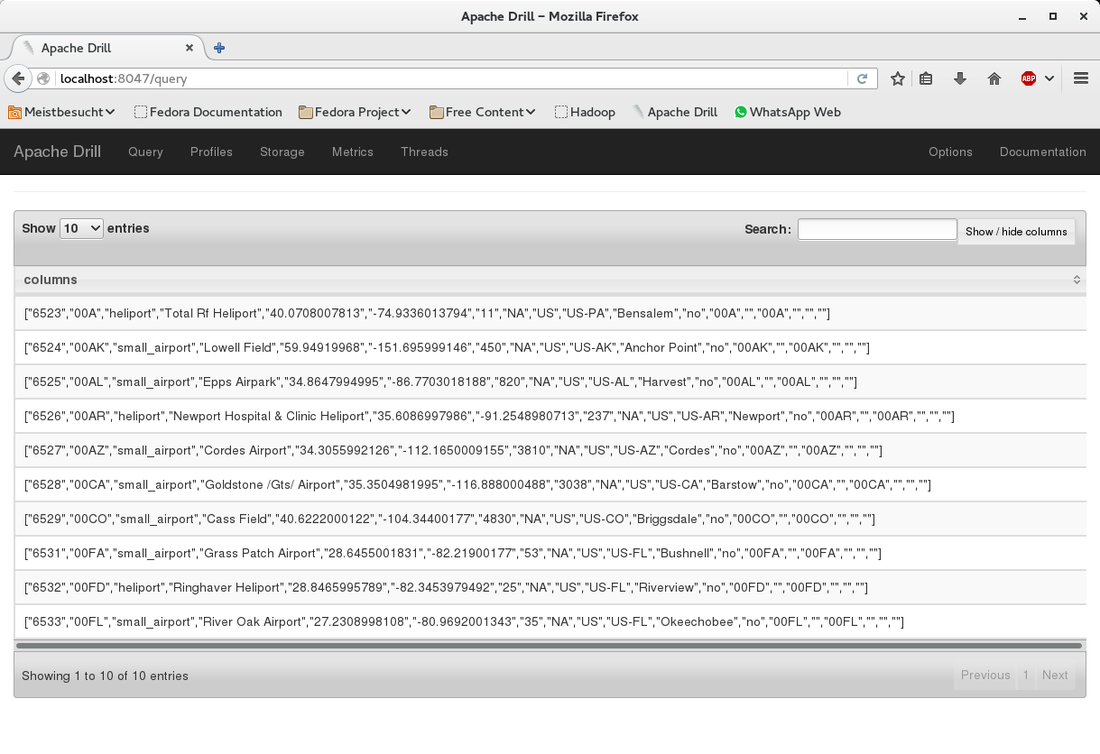
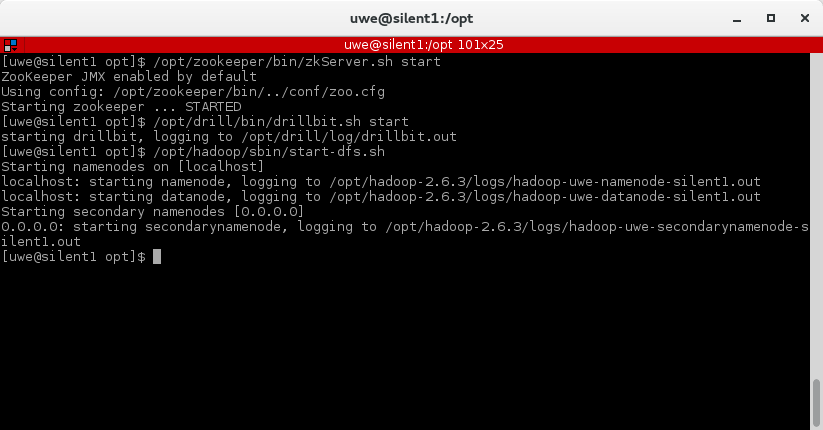
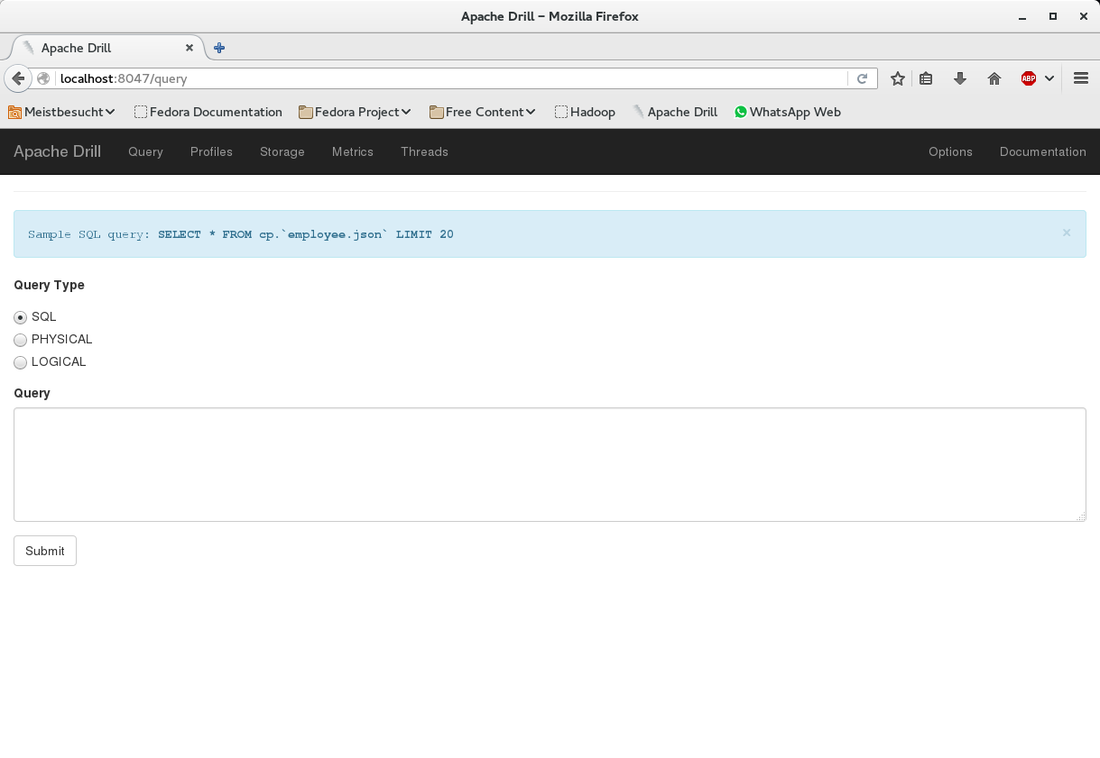
The first part of this post was about the basic setup and running Zookeeper, Drill and Hadoop HDFS. In this second part we will add a CSV file to HDFS and query it from Drill. 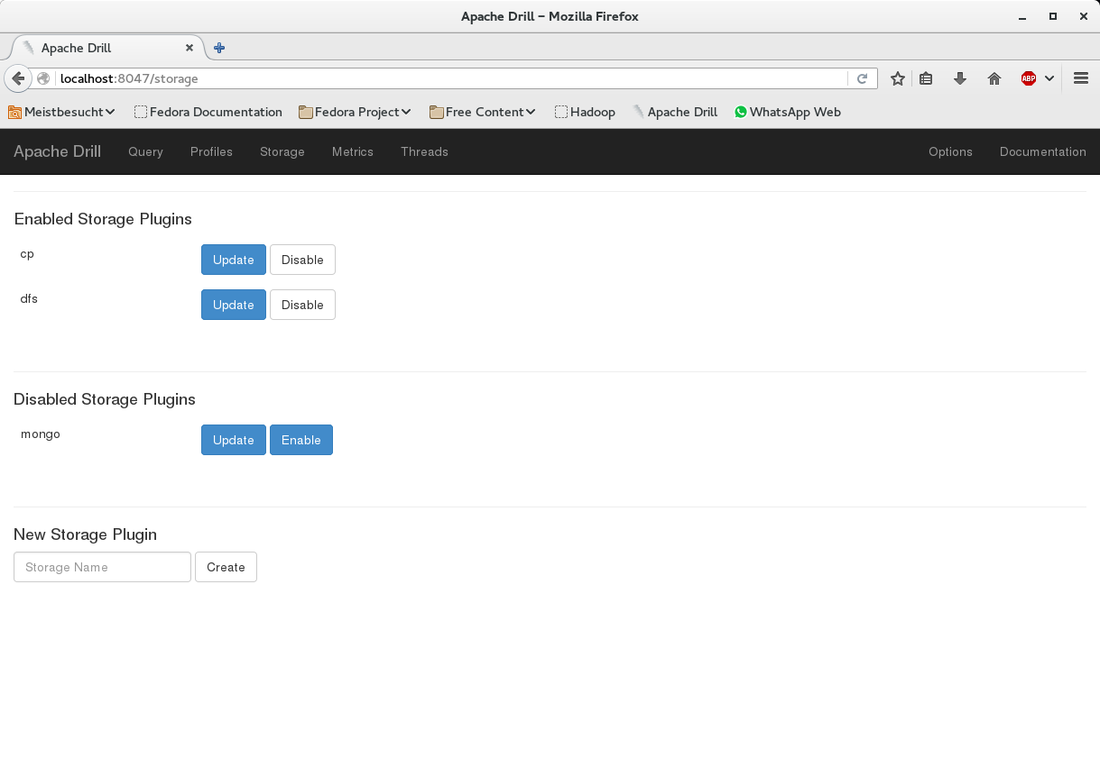 At the bottom under "New Storage Plugin" enter hdfs in the textbox and click on "create". You will see a page titeled "Configuration". I filled in the information as shown below. What you can also do is to copy the configuration of an existing storage plugin (e.g. "dfs") and modify it for the HDFS configuration. Basically you only need to change the values for "connection" and (workspace) "location". |
AuthorUwe Geercken Categories
All
Archives
September 2020
|

|
 RSS Feed
RSS Feed
