
This is the last part of three parts. The last time we have queried a CSV file in Hadoop HDFS from Drill.
This time we will use the Drill "create table as" statement to create parquet files in HDFS and use those for querying.
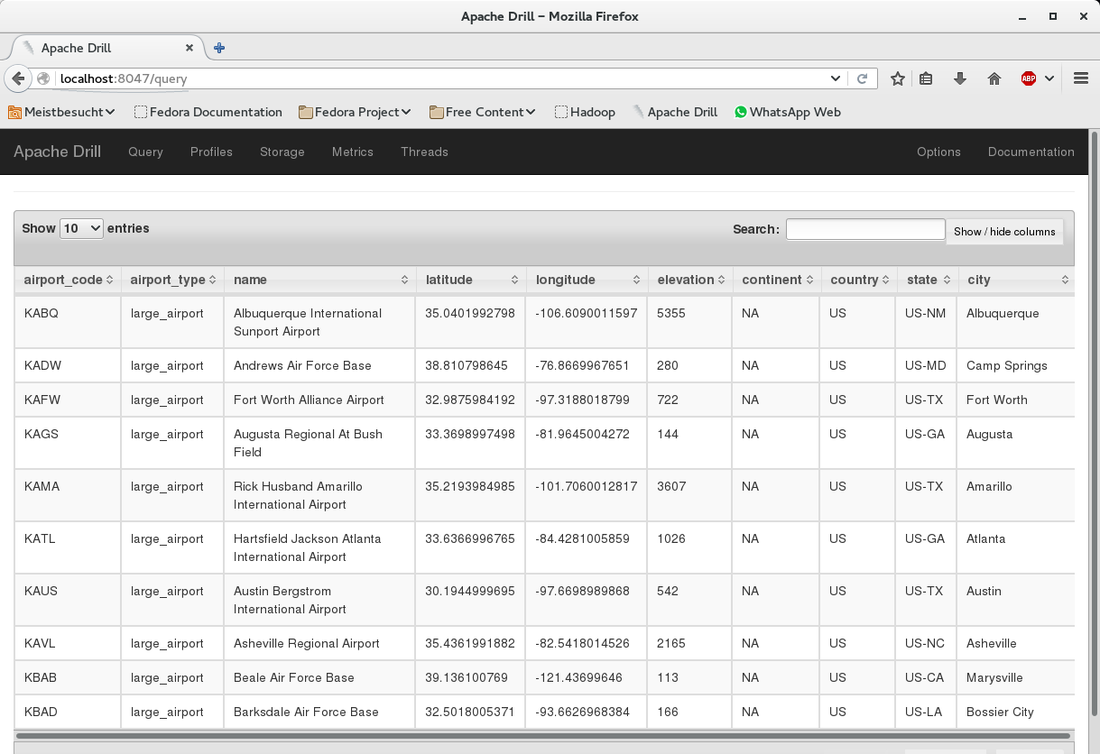
First we do a basic query against the CSV file in HDFS:
select
columns[1] as airport_code,
columns[2] as airport_type,
columns[3] as name,
columns[4] as latitude,
columns[5] as longitude,
columns[6] as elevation,
columns[7] as continent,
columns[8] as country,
columns[9] as state,
columns[10] as city
from hdfs.data.`/airports.csv` limit 10
We select the fields and run the query to see if it executes correctly.
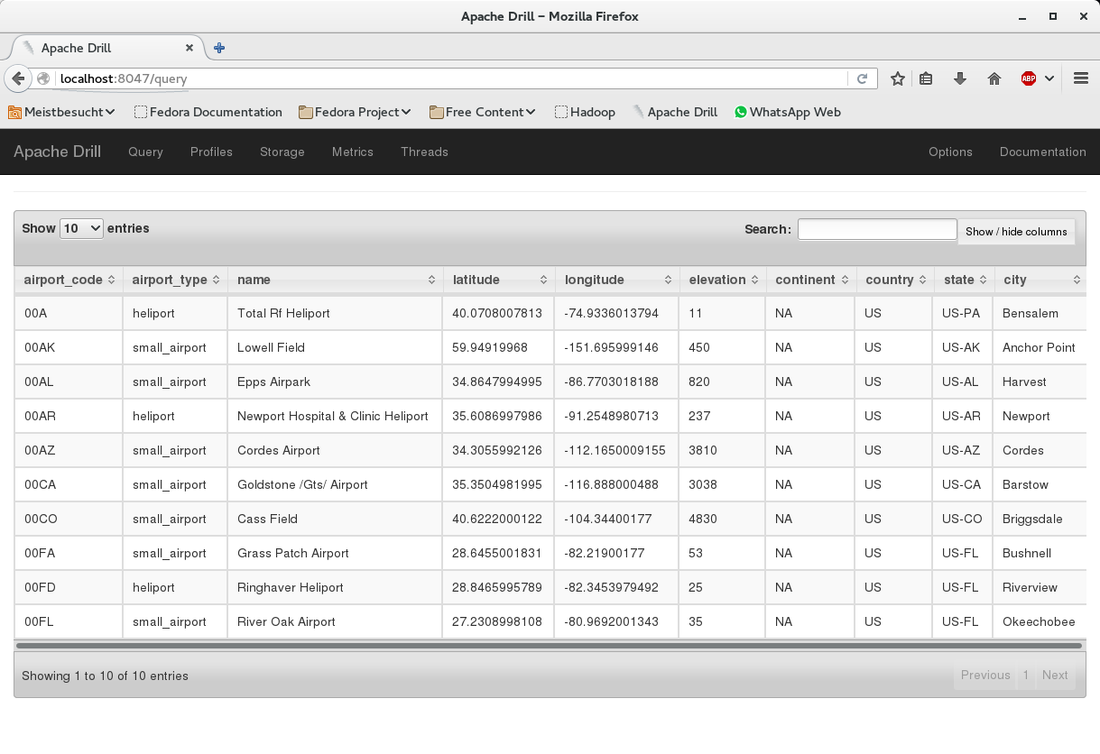
Now we will slightly change the query to create parquet files. Simply add the first line as shown below:
create table hdfs.data.`/airports_parquet` partition by(continent) as
select
columns[1] as airport_code,
columns[2] as airport_type,
columns[3] as name,
columns[4] as latitude,
columns[5] as longitude,
columns[6] as elevation,
columns[7] as continent,
columns[8] as country,
columns[9] as state,
columns[10] as city
from hdfs.data.`/airports.csv`
When you run the query it will create multiple files in the Hadoop filesystem because we have specified the "partition by" clause. For each continent in the CSV data a seperate file is created.
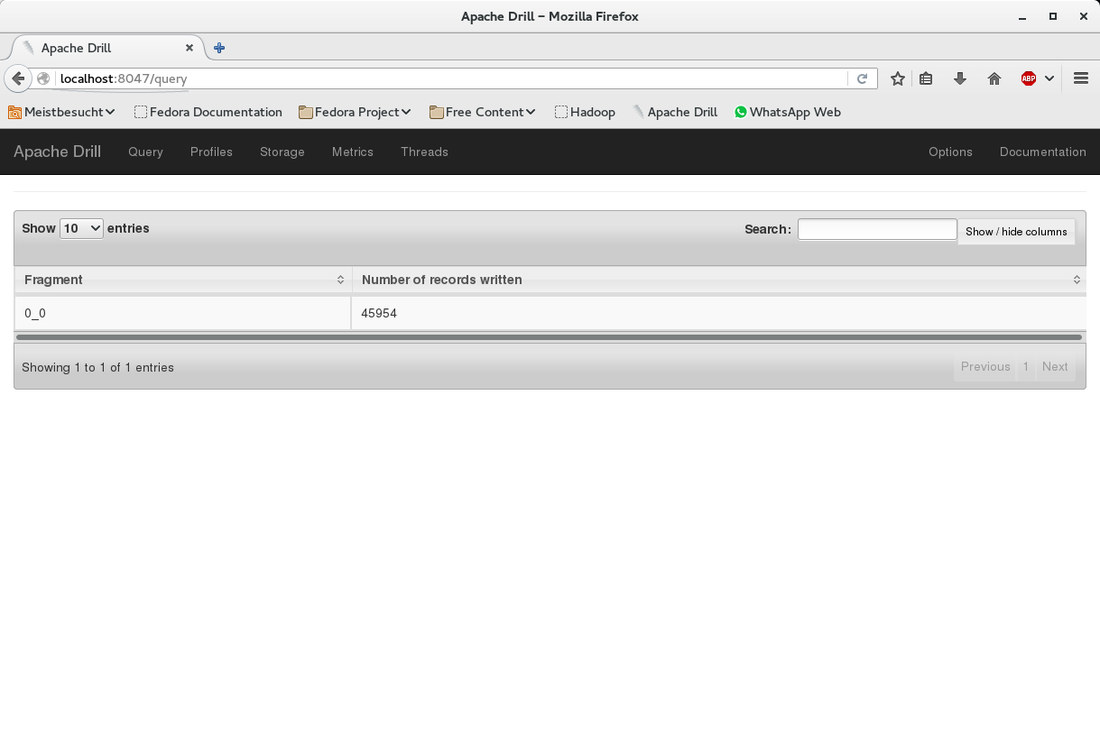
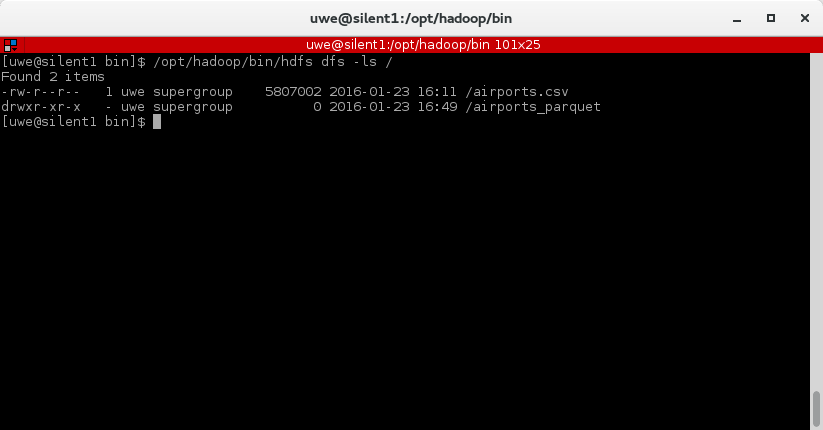
Go to the console window and check what has happened in the Hadoop filesystem:
/opt/hadoop/bin/hdfs dfs -ls /
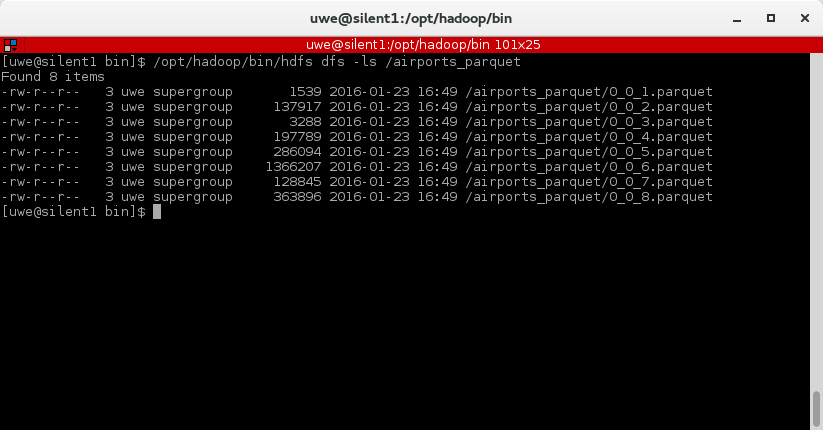
The folder "airports_parquet" was created as we used it as the table name in the "create table as" statement. Inside the folder there are the parquet files - one per continent:
Now that we have the parquet files created, we can use them to query the airport data. Here is an example:
select *
from hdfs.data.airports_parquet
where continent='NA' and country='US' and airport_type='large_airport'
This queries for large-type airports in continent North America in the US:
 RSS Feed
RSS Feed
