
So here is the second part of the starter for Apache Nifi.
The sample I worked from retrieves tweets from Twitter, pulles out some attributes and makes a decision to store the tweet or not based on these attributes.
While discovering and learning, I wanted to make a slightly more complicated flow. Bare with me, "complicated" is of course only relative - I have used Nifi for only two days...
You can see the result below. Here are the key points I wanted to achieve:
- Retrieve tweets only for some selected topics
- Devide tweets between those that are of my personal interest and those more work related
- Pull out those attributes that I later want to store in files (I do not want the whole tweet with all its attributes)
- Store the Json representation of the tweets in seperate folders for private and work related tweets.
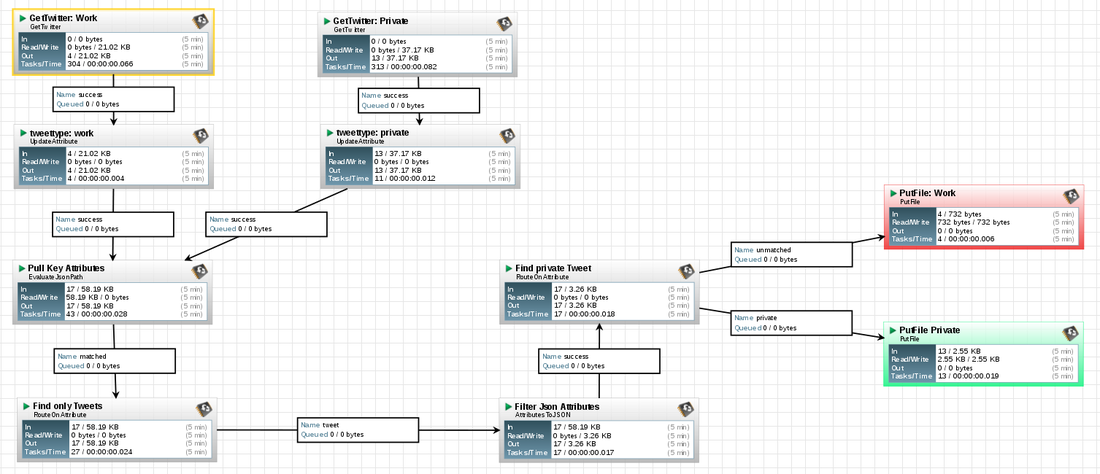
Apache Nifi works with processors and connections between them. That's what you see on the flow above. Processors are sort of puzzle pieces that do a distinct task and then you connect them together to design a flow.
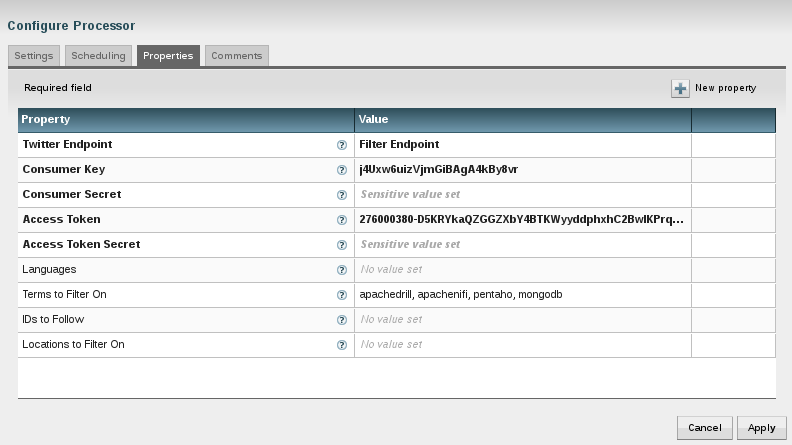
It starts in the upper left hand corner. There is a processor named "GetTwitter" and another one next to it. When you select "Configure" you get the dialog displayed below. The properties shown in bold are mandatory - they are security details required to access the tweets (get them from Twitter). I have entered four terms seperated by comma under "Terms to Filter on". Together with "Filter Endpoint" for the property "Twitter Endpoint", so that I receive only tweets that contain those terms.
As described above I have two of these "GetTwitter" processors. One retrieves tweets for the terms shown below and the other one for different terms - I wanted to separate work related tweets from private ones.
The screenshot shows the configuration dialog for the selected processor.
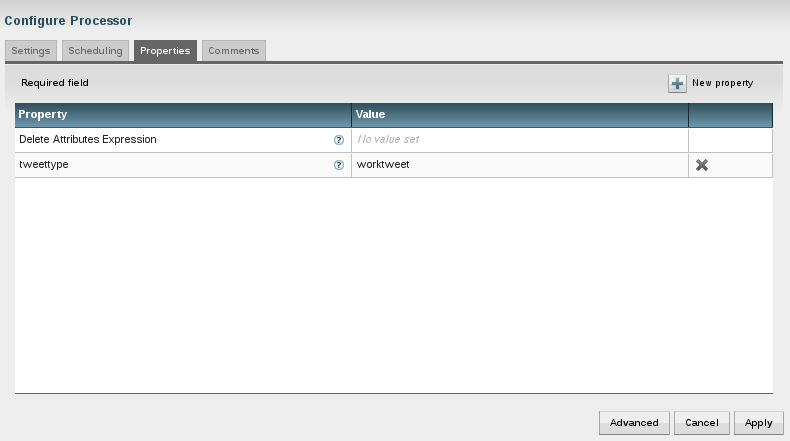
Now the questions was how to use a common processing flow for both "GetTwitter" processors - not to duplicate things - and yet being able to devide the results into seperate files later on. I used the "UpdateAttribute" processor. It allows to assign properties, so I am tagging my different flows: they get a property named "tweettype" of "privatetweet" versus "worktweet".
After this, the both path flow into the "EvaluateJsonPath" processor. This processor pulls out some attributes from the tweet.
Next comes a "RouteOnAttribute" processor. It evaluates, if the tweet actually has a message assigned. So tweets without a message (an empty message) will be dropped. It uses the Nifi Expression Language to make the evaluation.
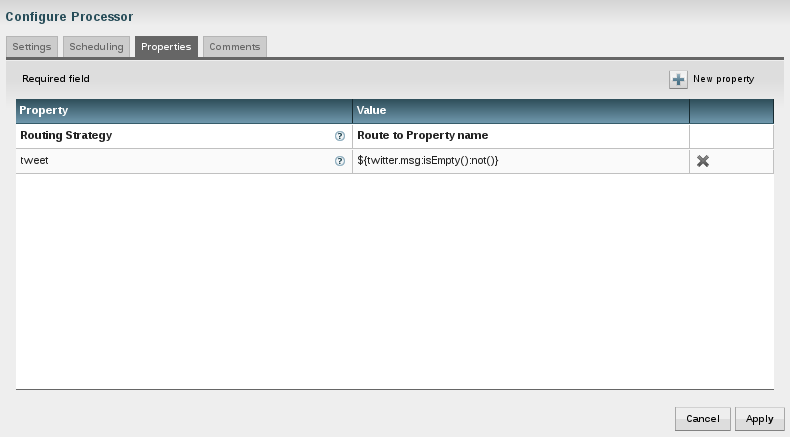
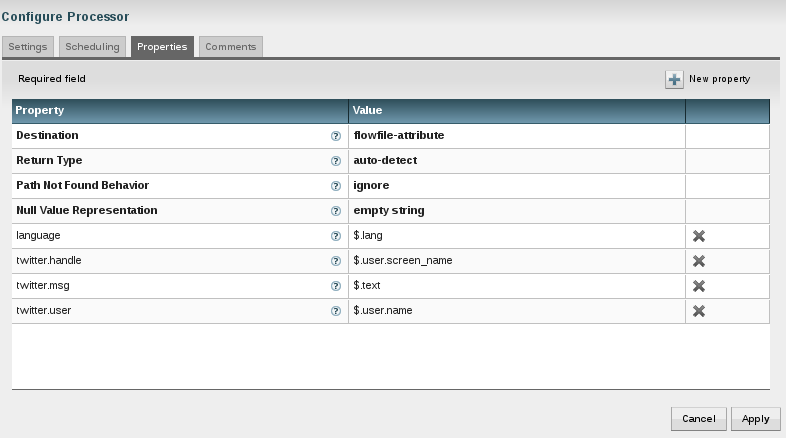
Twitter tweets - in the form of Json data - contain a lot of information. Information I don't want to store. I am only interested in the information about the user and the message itself. So I had to look for a way to eliminate the rest of the information in the flow.
The "AttributeToJson" processor allows me to do this. I specified a list of attributes which I wanted to keep for the property "Attribute List". It is important to set the property "Destination". By setting it to "flowfile-content" I am overwriting the content of the Json file (the tweet) with these attributes.
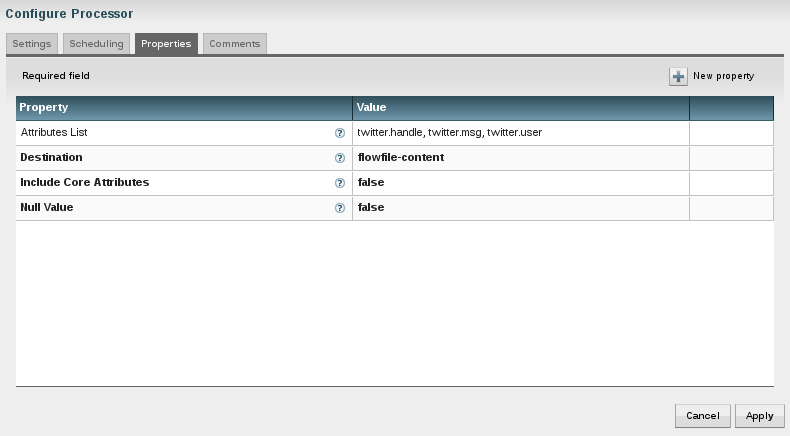
I have setup my main logic by now. Now I want to store the results in two seperate folders - one for private tweets and one for work related tweets. I will evaluate the property "tweettype" which I assigned earlier and make the decision to route the data based on the value of this property.
I call the new property "private" and use a Nifi expression to check if the "tweettype" contains the value "privatetweet". I use the "RouteOnAttribute" processor for this.
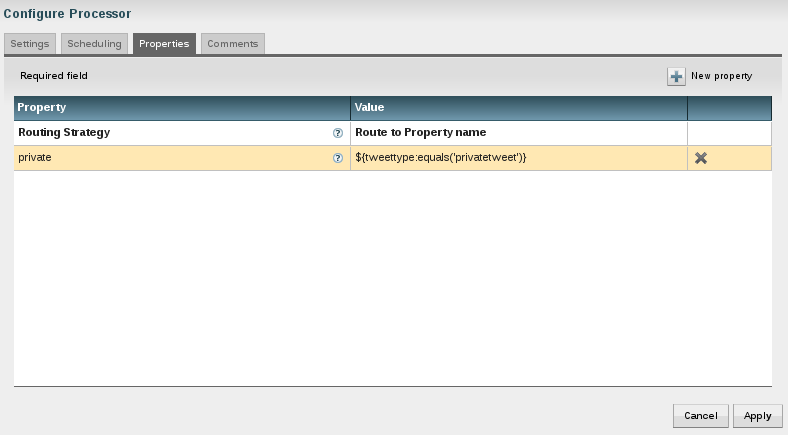
The property "private" will result in a true or false condition and when I connect the processor I can route the results based on this true or false condition. If property "private" is true, the result is routed to the "PutFile: Private" processor. If not then it is routed to the "PutFile: Work" processor.
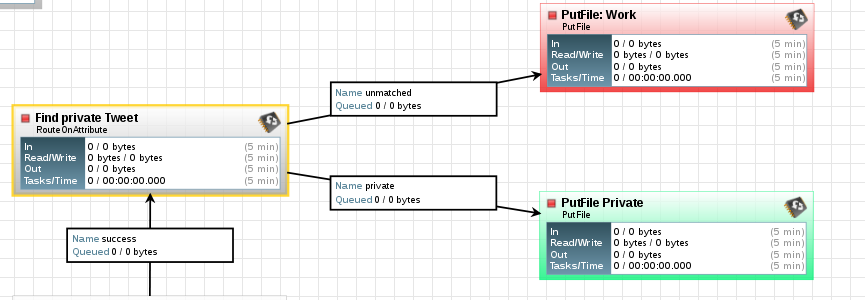
The "PutFile" processor saves the file to a given folder. I have setup two folders, one for the work related tweets and one for private ones. The property "Directory" defined where the file shall be stored.
 RSS Feed
RSS Feed
